LCEC
LCEC
Abbreviations
LCEC: Lidar-camera extrinsic calibration
SoTA : state-of-the-art
LVMs: large vision models
LIP image: LiDAR point intensities are projected into the camera perspective, thereby generating a virtual image,which is a LIP image
C3M: (Cross-Modal Mask Matching)a novel and robust cross-modal feature matching algorithm, capable of generating dense and reliable correspondences
Explanation of terminology
Target-Based
need specialized calibration targets
用标定板
Target-Free
上面的反义词
History
手动选择correspondences
traditional line/edge feature-based 出现,激光雷达点强度投射到相机视角中,生成LIP图像,在LIP和RGB图上进行边缘检测,匹配
最大化 LIP 和 RGB 图像之间的mutual information(MI),优化外参
PnP
Three approaches
1. Target-based calibration
The challenge here is that it is often difficult to design and create a calibration target that can robustly and accurately be detected by both the LiDAR and the camera
2. Motion-based calibration
it requires careful time synchronization, which is not always possible when, for example, we use an affordable web camera
furthermore, we need to estimate the per-sensor motion as accurately as possible for better calibration results
3. Scene-based calibration
Scene-based methods estimate the LiDAR-camera transformation by considering the consistency between pairs of LiDAR point clouds and camera images. LiDAR points are projected in the image space, and then their consistency is measured with pixel values based on some metrics.
indirect: extracts feature points (e.g., edge points)
direct: compares the pixel and point intensities directly
Existing Challenges
1. line/edge feature-based
- 效率高,但是需要特定场景,不能检测球或圆柱
- 当场景中边缘主要朝一个方向排列的情况下,约束条件可能不足以唯一确定外参,可能收敛于局部最优
- 图像中边缘分布不均会导致约束不强,容易受到测量噪声的影响
2. point feature-based
需要有独特的二维图像像素和三维激光雷达点,并且强度或深度在所有维度上都有显著变化,因此可能会导致缺乏可行的对应关系,尤其是在低纹理环境中
为什么“需要有独特的二维图像像素和三维激光雷达点” ?
通常会忽略激光雷达和相机之间视场 (FoV) 的对齐,导致激光雷达点云中出现过多无关点,不利于calibration的稳定
3. semantic feature-based
主要依赖于设计过的、预先定义的对象
eg:车辆 、车道 、电线杆和停车标志
场景变换(由外观、光照条件或物体分布的差异引起)和注释不一致(不同数据集通常有不同的注释)影响算法在新的、未见过的场景中的泛化能力
Researches
MIAS-LCEC
Online, Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
pipeline
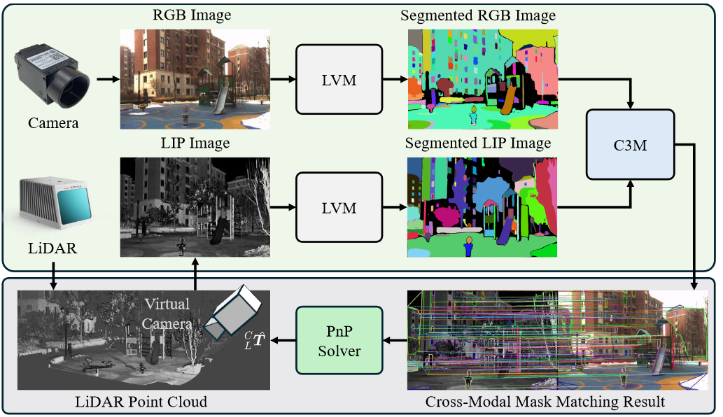
创建一个虚拟相机,从该相机的视角去将雷达的点云投影到2D,获得一个LIP图,解决了fov对齐问题
“虚拟相机的位置是迭代更新的”,是为了和RGB相机的pose相同和不断迭代吗?
更新直到 LIP 图像与实际摄像机透视图相似为止
使用 MobileSAM 对 LIP 和 RGB 图像进行分割,分割结果随后用C3M算法找到correspondence
得到的对应关系用PnP ,得到外参
核心算法:C3M
该算法能够生成稀疏但可靠的匹配,并将其传播到目标掩码进行密集匹配
C3M有两个步骤
- 获得稀疏但可靠的匹配
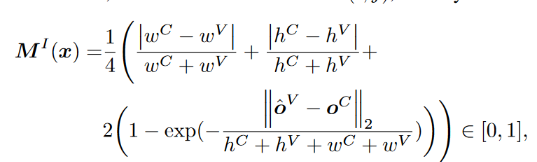
对于SAM分割的结果先进行instance匹配,使用上图的公式计算cost,这里考虑了instance的大小(长宽,论文中称为水平和垂直方 向上的cost),以及instance质心之间的距离,但是大小相近的话,质心的距离影响不大
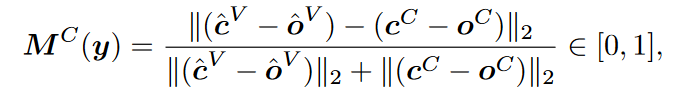
然后进行instance中的corner points的匹配,使用上图的公式,
通过上面的匹配计算s,R,T,将LIP图仿射变换,通过变换后的LIP图和原来的RGB图寻找稠密的匹配
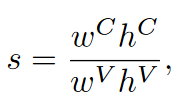
s:面积比
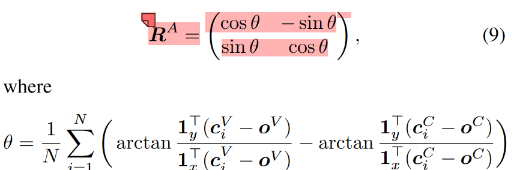
R:通过计算角度来确定,每一组匹配的corner points都计算一次角度,最后求均值,每个角度计算质心到对应corner point的向 量的夹角
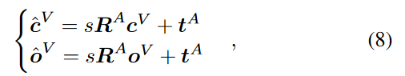
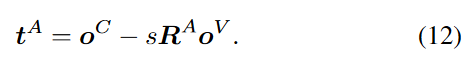
t:因为(8),目标OV的估计值最好是OC,所以这里之间用OC来计算T
得到s,R,t之后将LIP图更新,更新后重复1的cost计算,就可以得到稠密的correspondence,然后用PnP求解
DVL
General, Single-shot, Target-less, and Automatic LiDAR-Camera Extrinsic Calibration Toolbox
pipeline
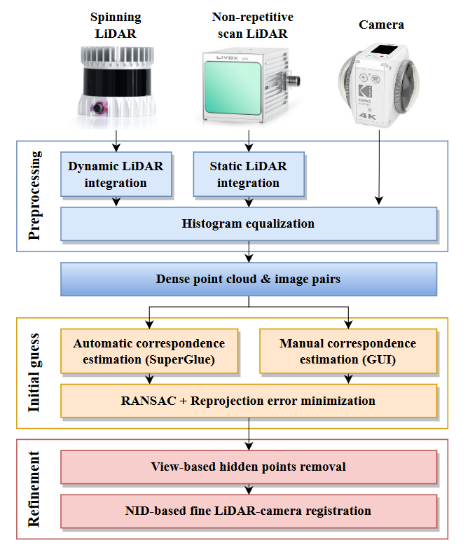
spinning lidar 通过累计多帧,static lidar simply accumulate points,来获得稠密点云
点云和image通过superglue找到2D-3D的correspondences,同时也提供了手动标注correspondences的GUI方法。然后用RANSAC 和 reprojection error minimization获得初始的T
删去相机视角中不应该看到的点云(相机FOV的限制),用NID minimization修正T
HKU-Mars
Pixel-level Extrinsic Self Calibration of High Resolution LiDAR and Camera in Target-less Environments
pipeline
Edge Extraction
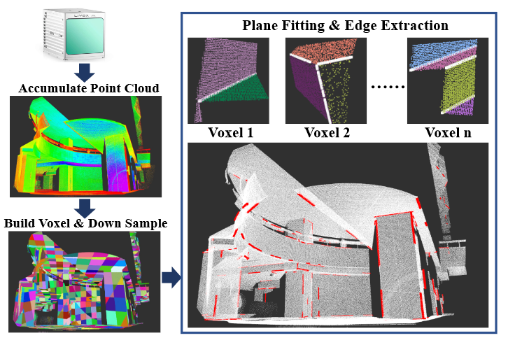
点云构建voxel,对于每个voxel,用RANSAC找平面,保留在一定范围内(例如 [30°,150°])相连并形成角度的平面对,并求解平面交叉线
这是为了寻找深度连续的边缘,减小误差
image用canny做边缘检测,找到的边缘像素存在k-D树用于后面的匹配
matching
点云检测的每条edge取几个点投影到2-D平面,去畸变后用k nearest找correspondences,同时将edge的方向投影到2-D,验证和找到点所在直线的法向量是否正交,筛除不平行仅仅是靠近的错误匹配
Extrinsic Calibration
先rough calibration,迭代优化P.C.最大(即优化有匹配的点云数量占点云总数的比例最大)
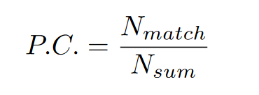
后精确标定