RNN
Recurrent Neural Network 循环神经网络(RNN)
example application
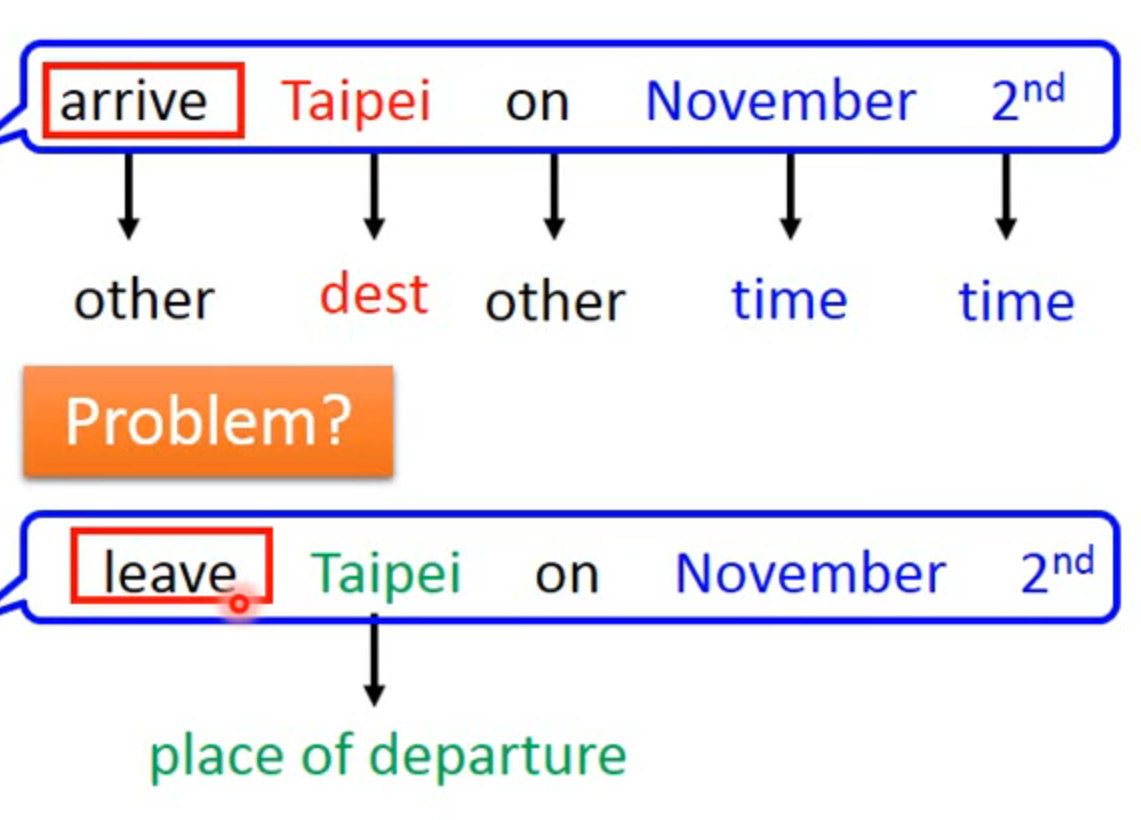
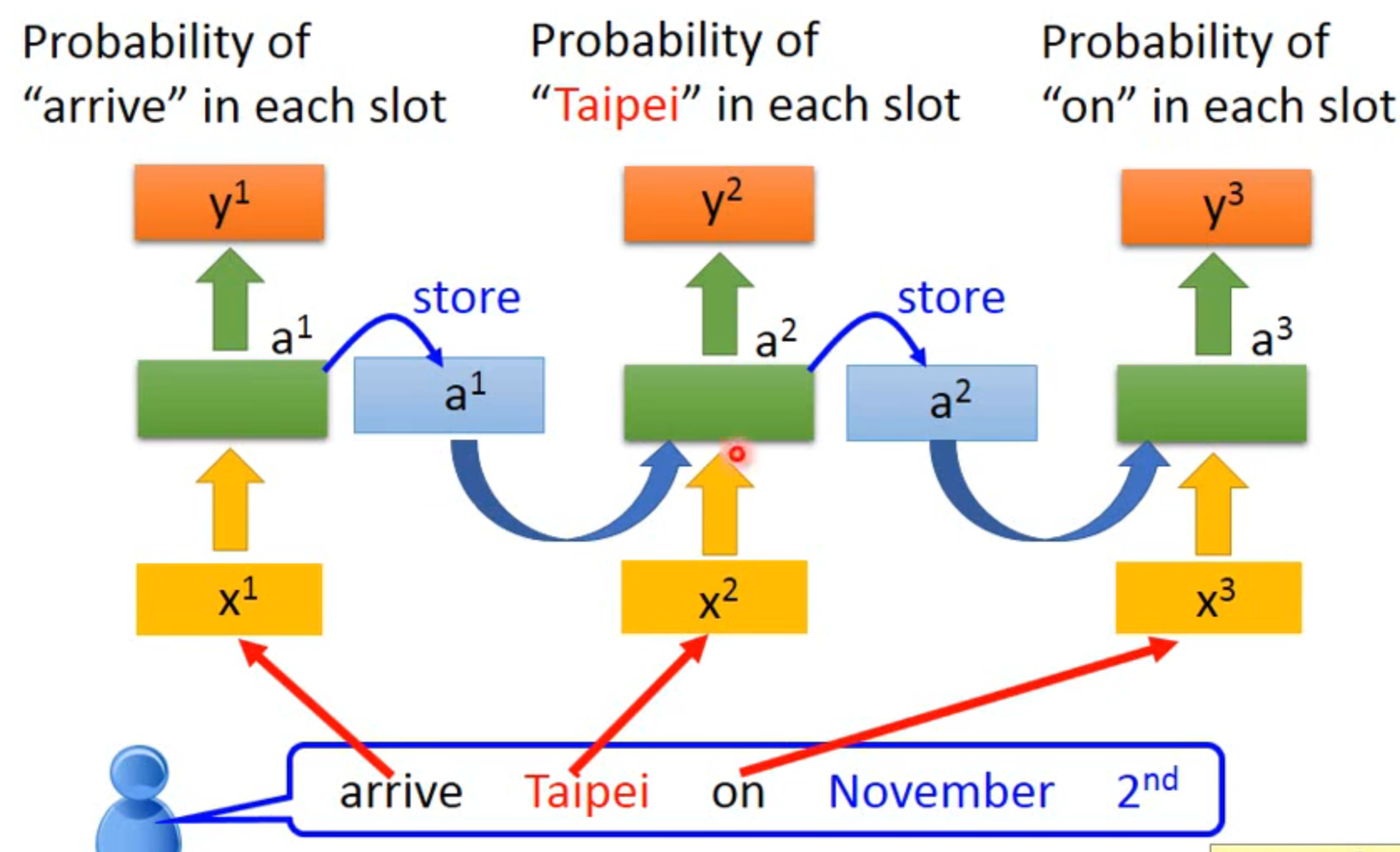
slot filling:智慧客服订票系统
taibei同样是输入,但是一个要输出为目的地,一个要输出为出发地
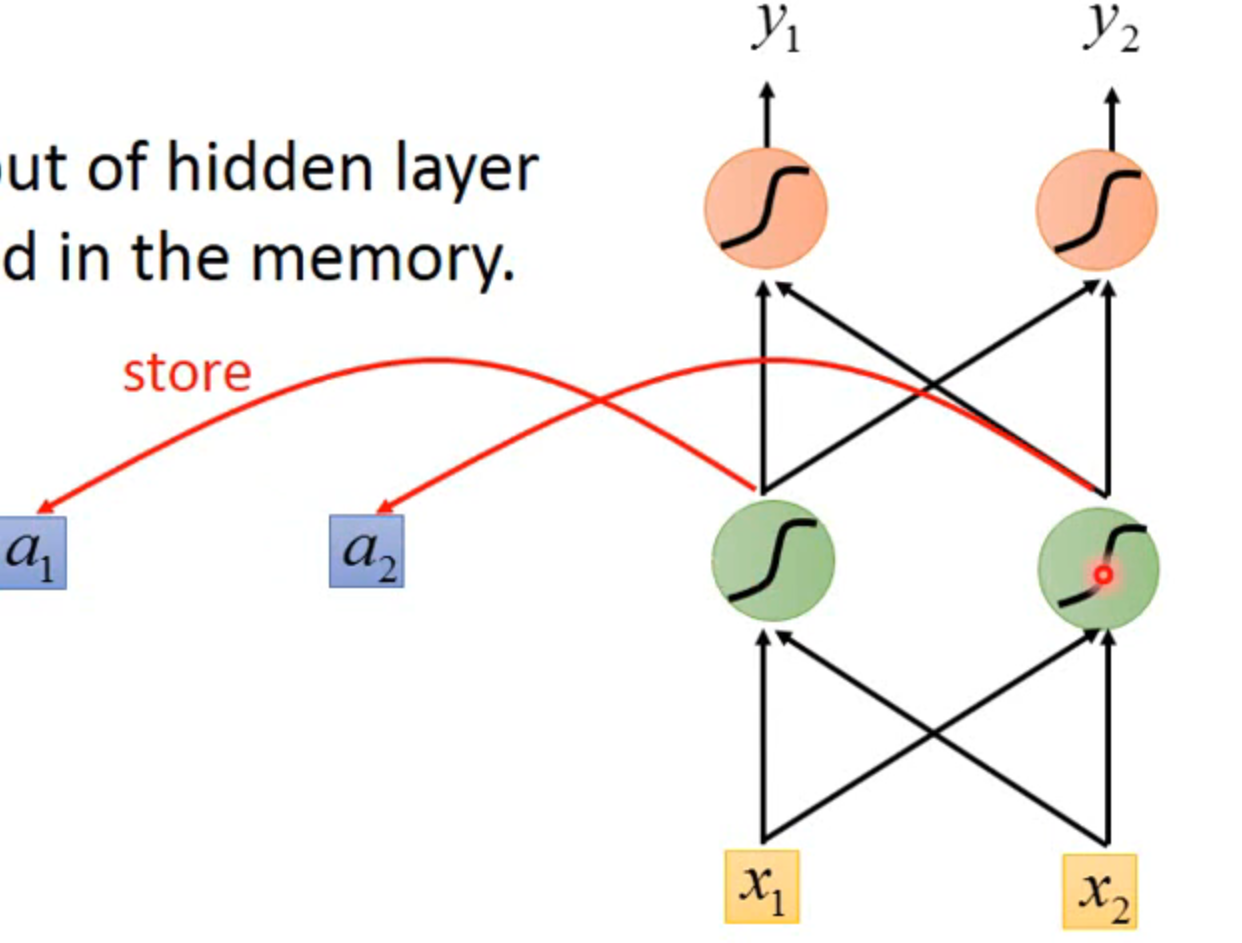
RNN
the output of hidden layer are stored in the memory
在还未开始之前需要在memory中放入起始值
example
all the weight are 1,no bias
all activation functions are linear
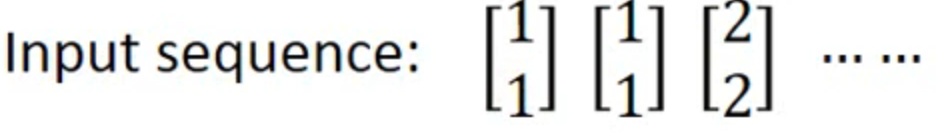
输入【1,1】之后,输出【4,4】,存入【2,2】
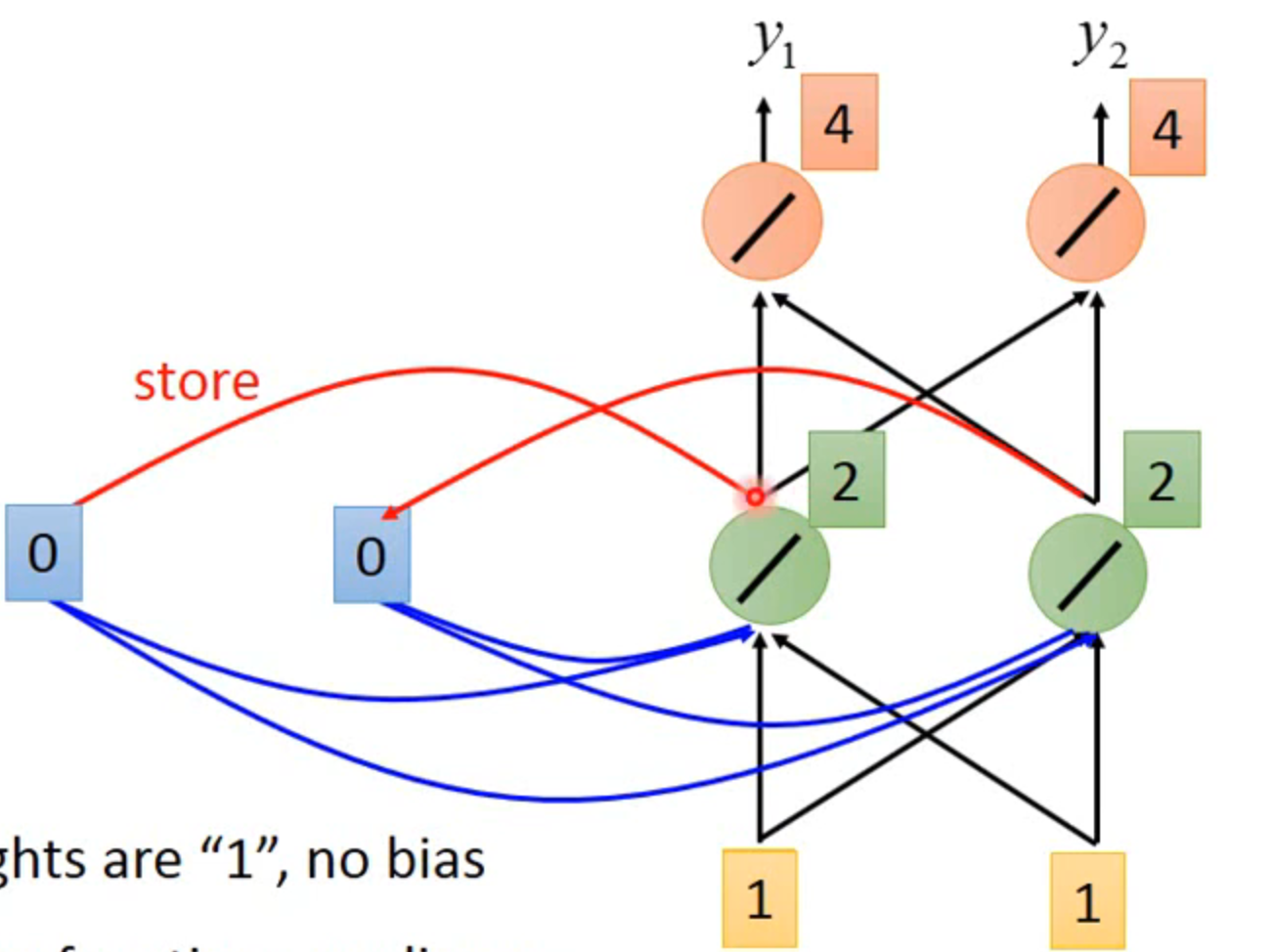
第二次输入【1,1】,第一层hidden layer输出是1+1+2+2和1+1+2+2,最终输出【12,12】,相同的输入产生了不同的输出
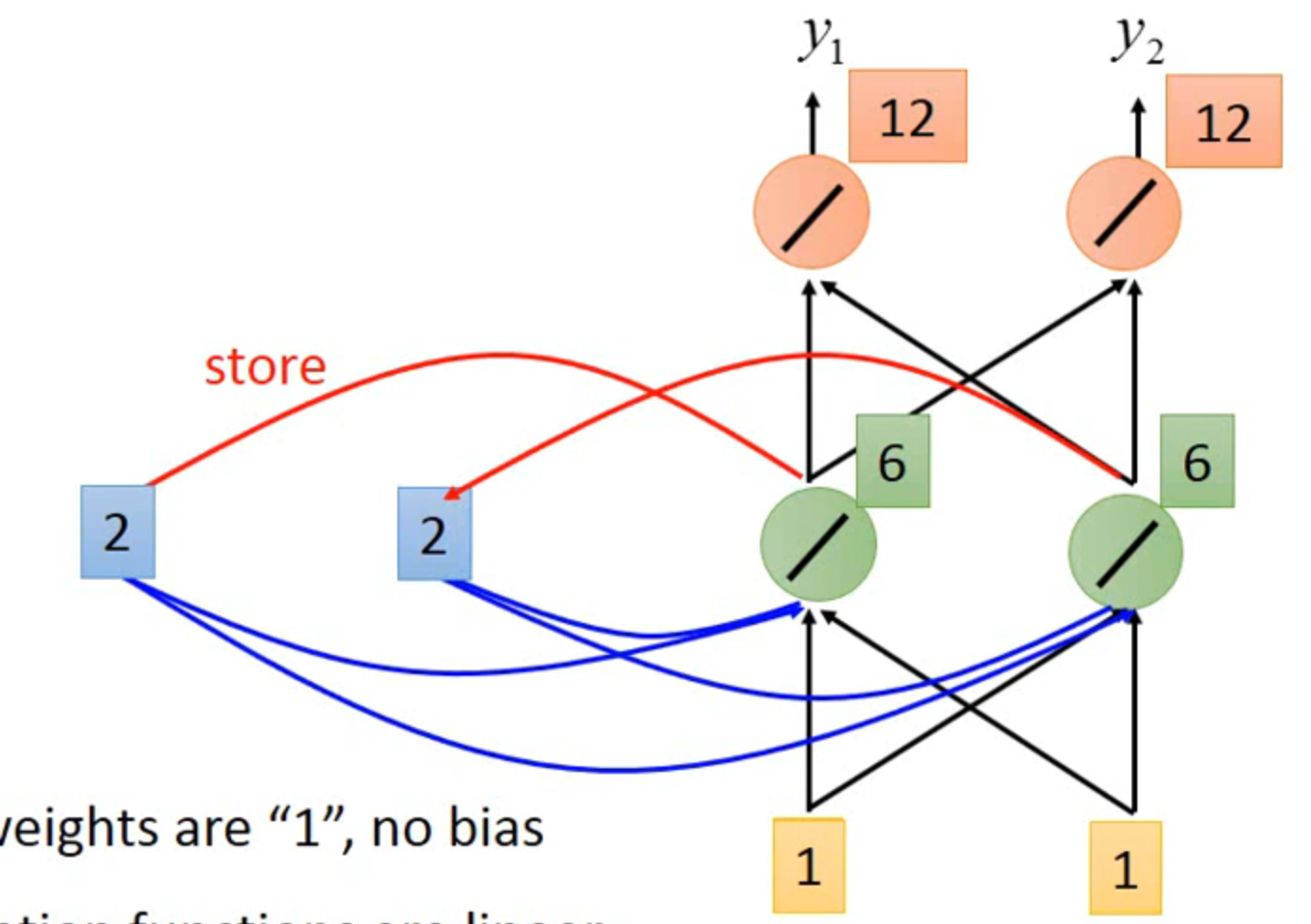
所以改变输入的顺序也会改变输出值
explain
是相同的三个network在不同的时间被使用了三次
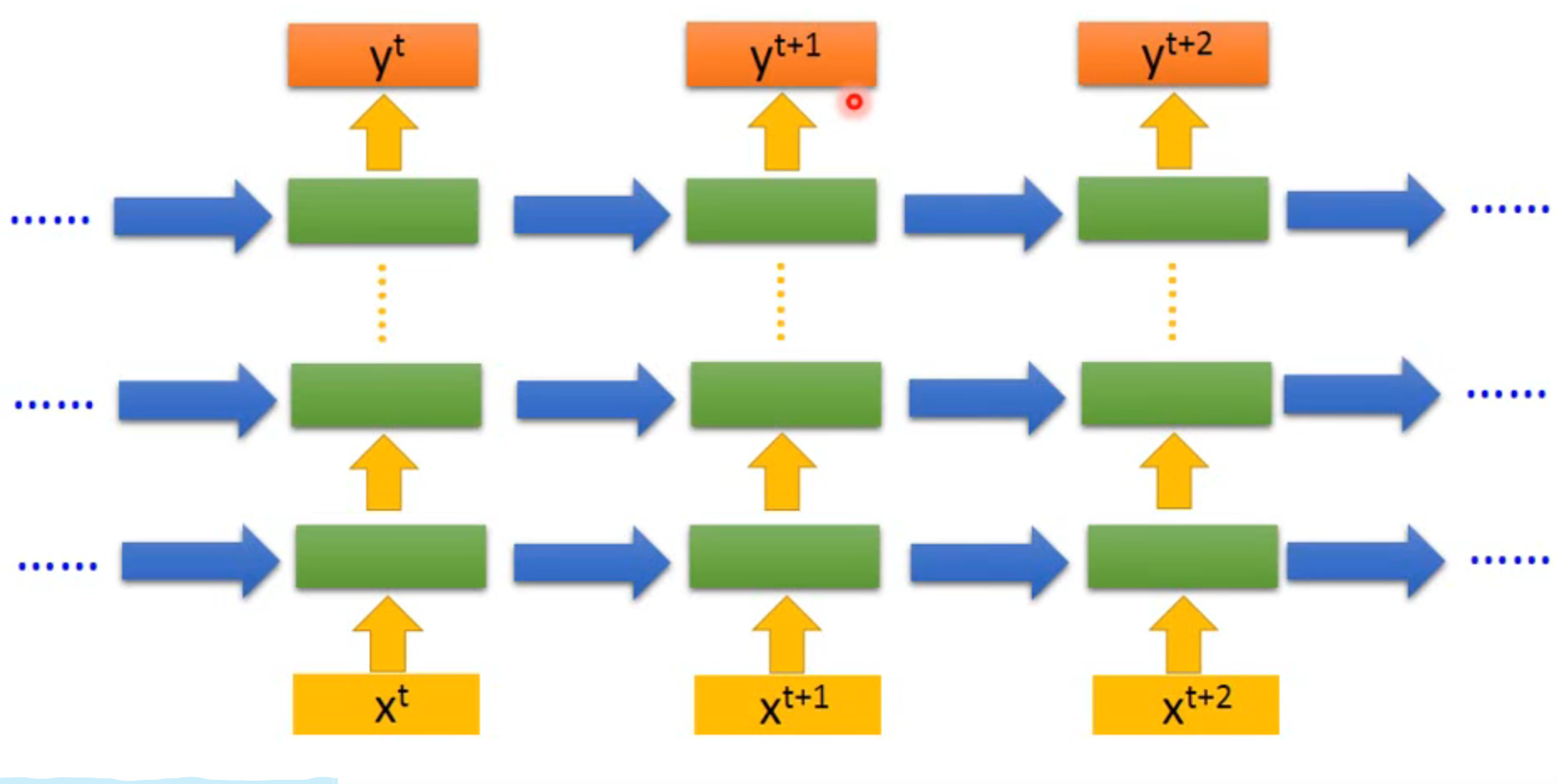
of course it can be deep
different kinds
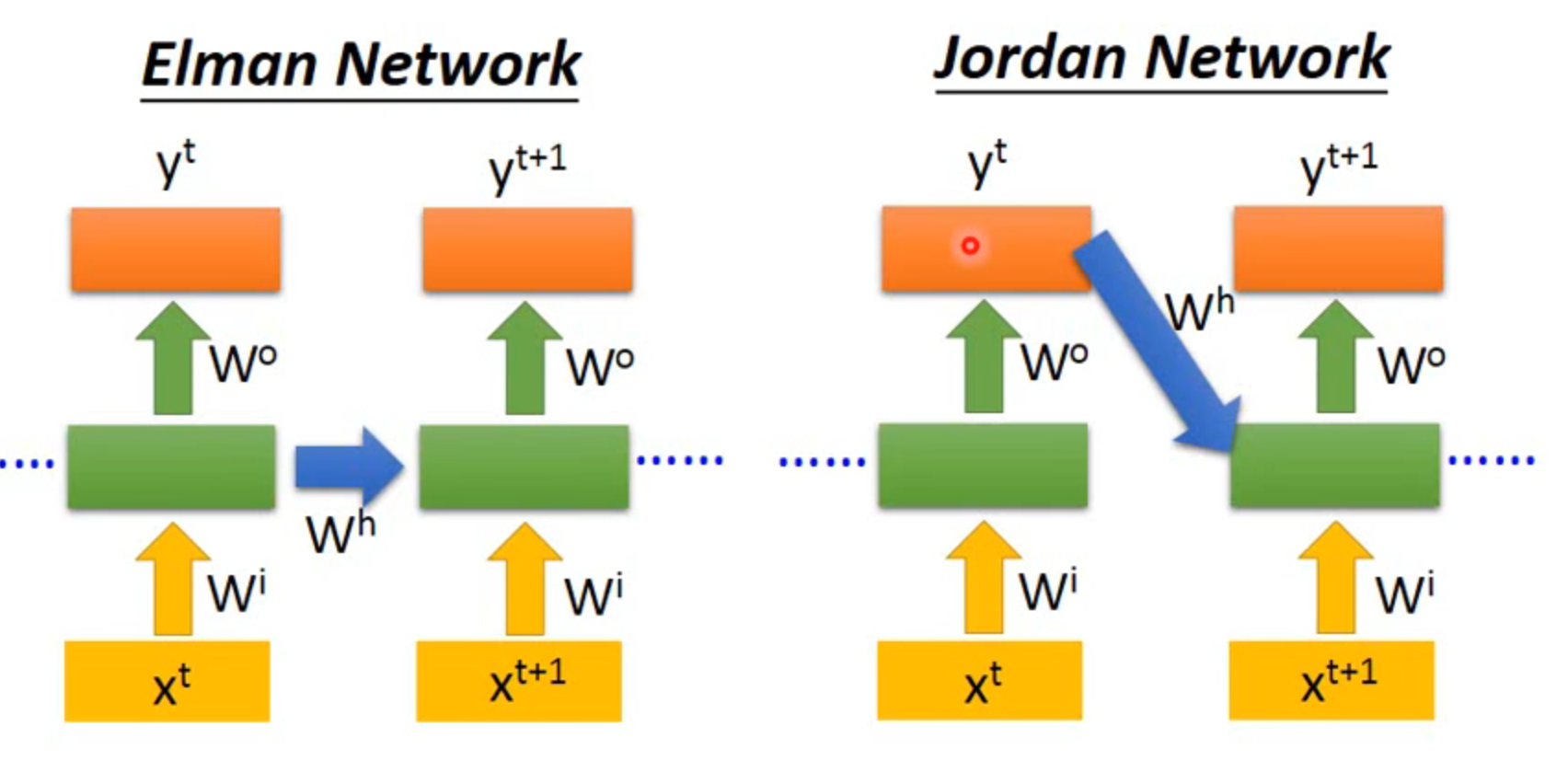
Elman network VS Jordan network
因为Jordan存储的是y,y在训练中有target,所以Jordan的表现更好
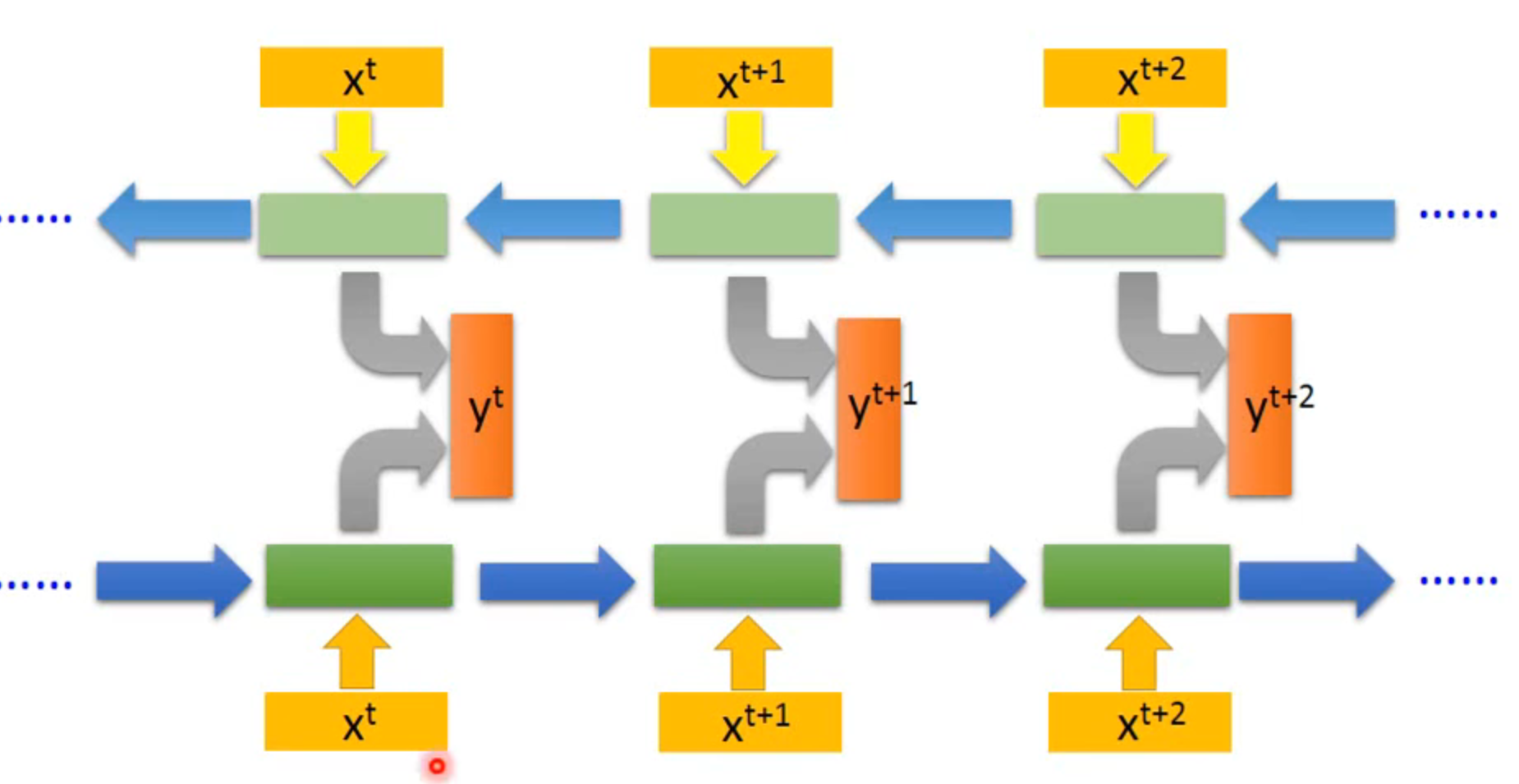
Bidirectional RNN 双向RNN
一个正着读,一个反着读数据,然后两者的hidden layer合并,产生输出,此时可以同时考虑前后的数据
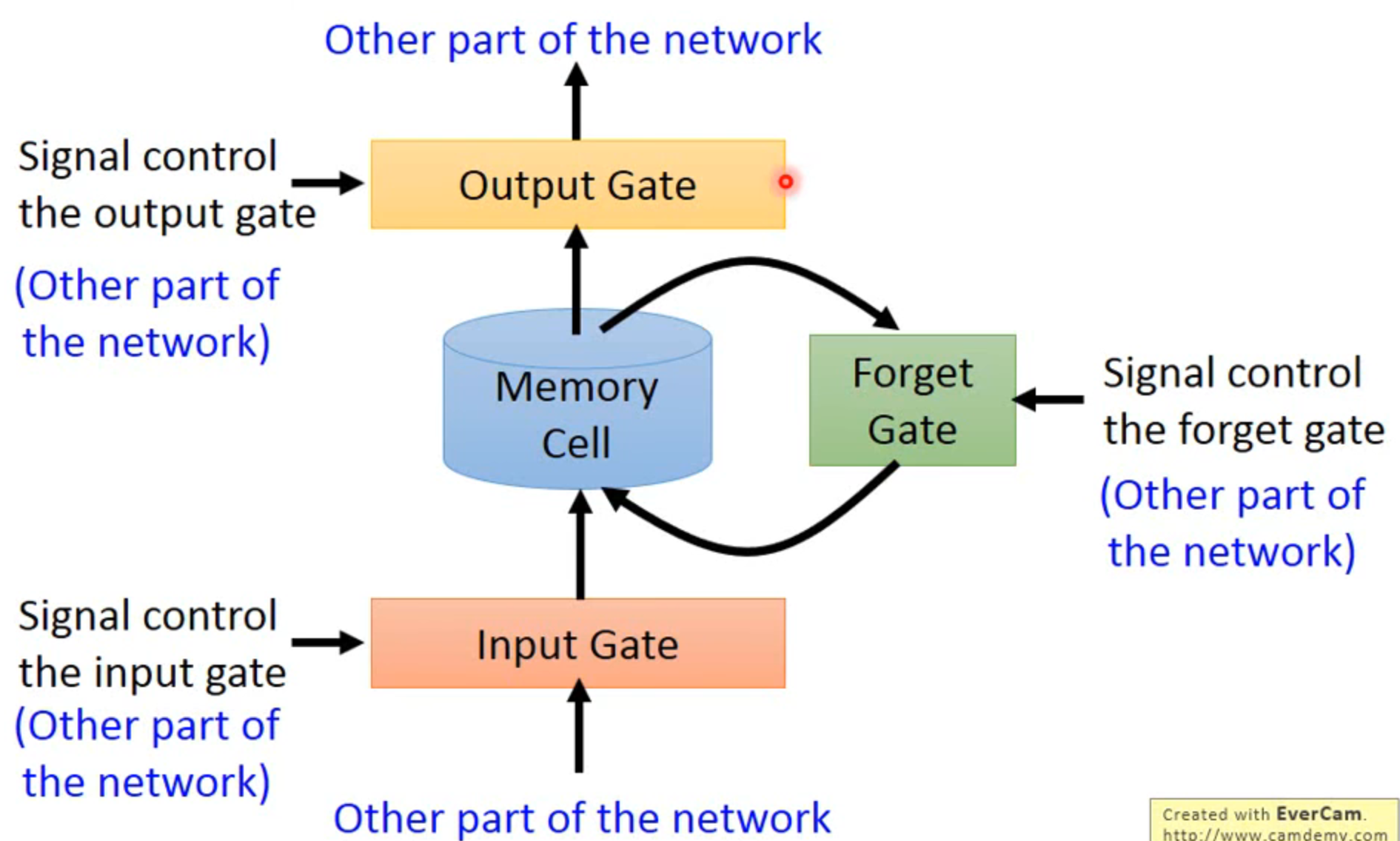
Long Short-term Memory (LSTM)
- 输入输出和遗忘都由其他的输入控制,这些都由神经网络自己学习
- 4个输入:1输入数据,2控制input gate,3控制output gate,4控制forget gate,所以LSTM的参数量是常规的4倍
- 一个输出
- 得名原因:因为forget gate的存在,memory中数据的存储时间比之前每次有新的输入就刷新要长,是比short-term memory 要long的系统
每一个gate一般都是一个sigmoid function,因为范围属于0到1
判断开关门实际上是gate函数输出值和要判断的值相乘,如果gate值接近0,就相当于该值不输入,被关在门外
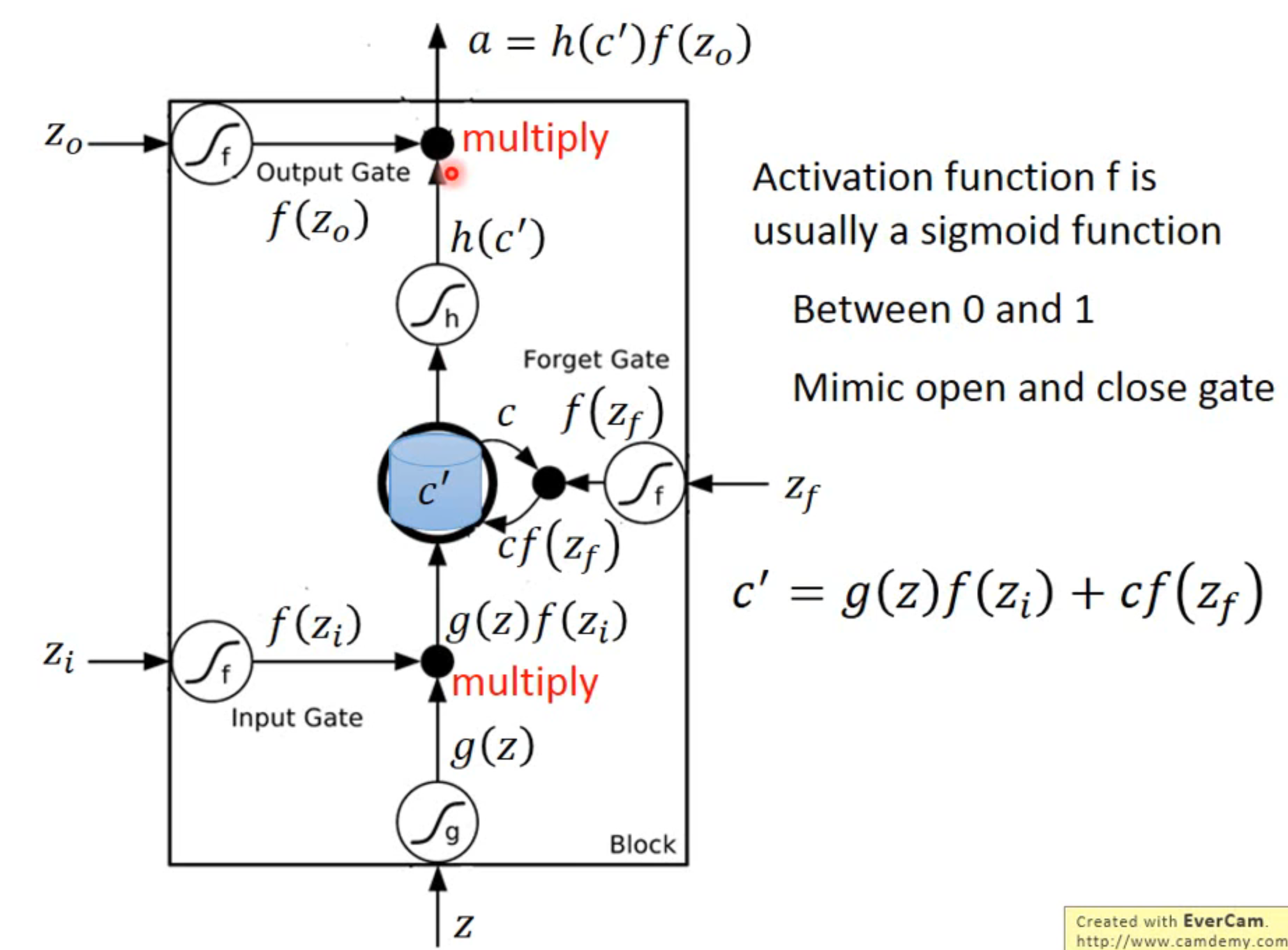
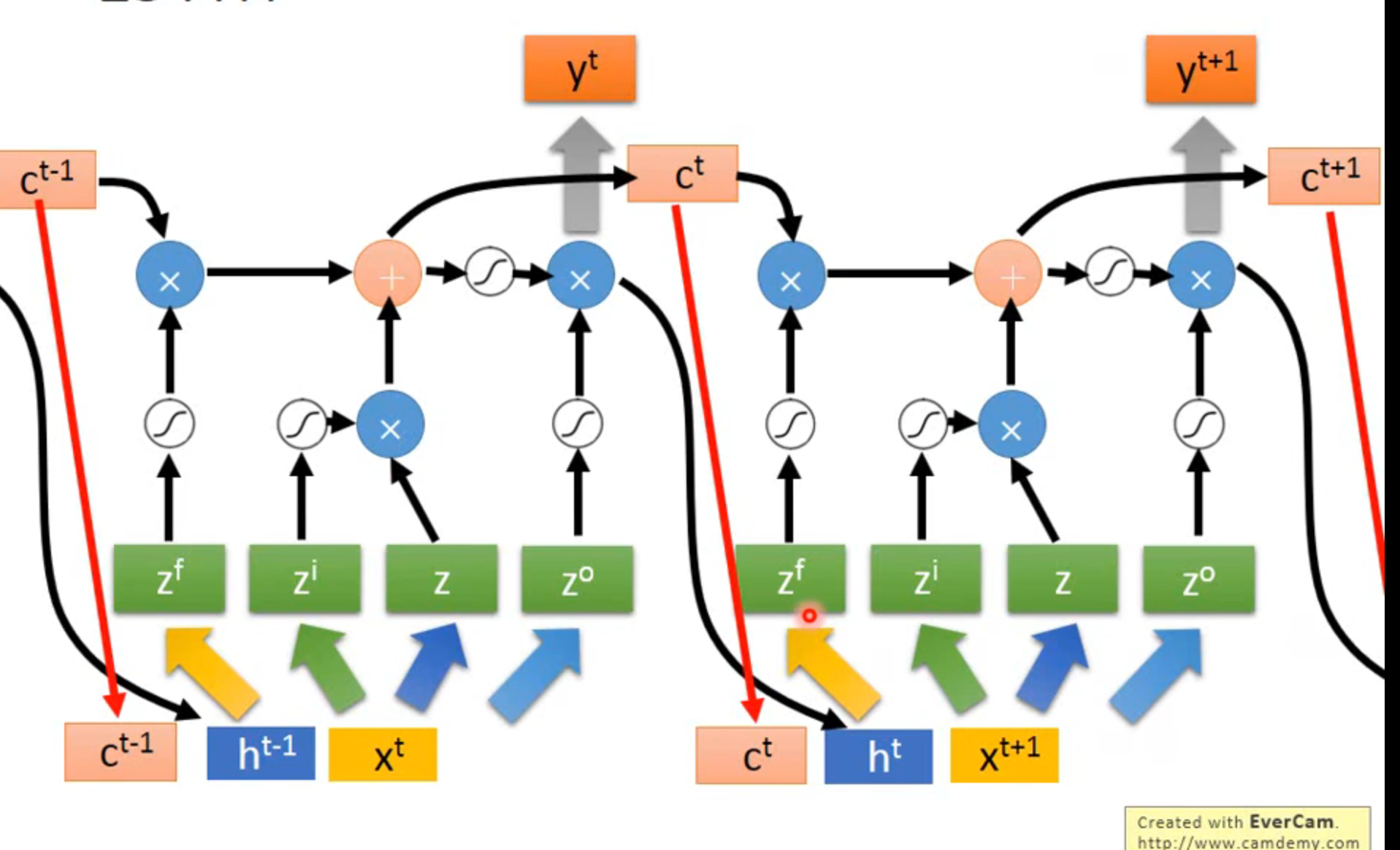
实际上输入端由x,之前存在cell的值,之前hidden layer的值共同与四组不同的参数相计算得到四个输入zf,zi,z,zo
Gated Recurrent Unit (GRU)
LSTM的简化版本,只有三个门,input和forget相关联,合并为一个gate
learning
依然是梯度下降来最优化
使用backpropagation through time (BPTT)来计算
但RNN很难训练,经常出现绿线的情况
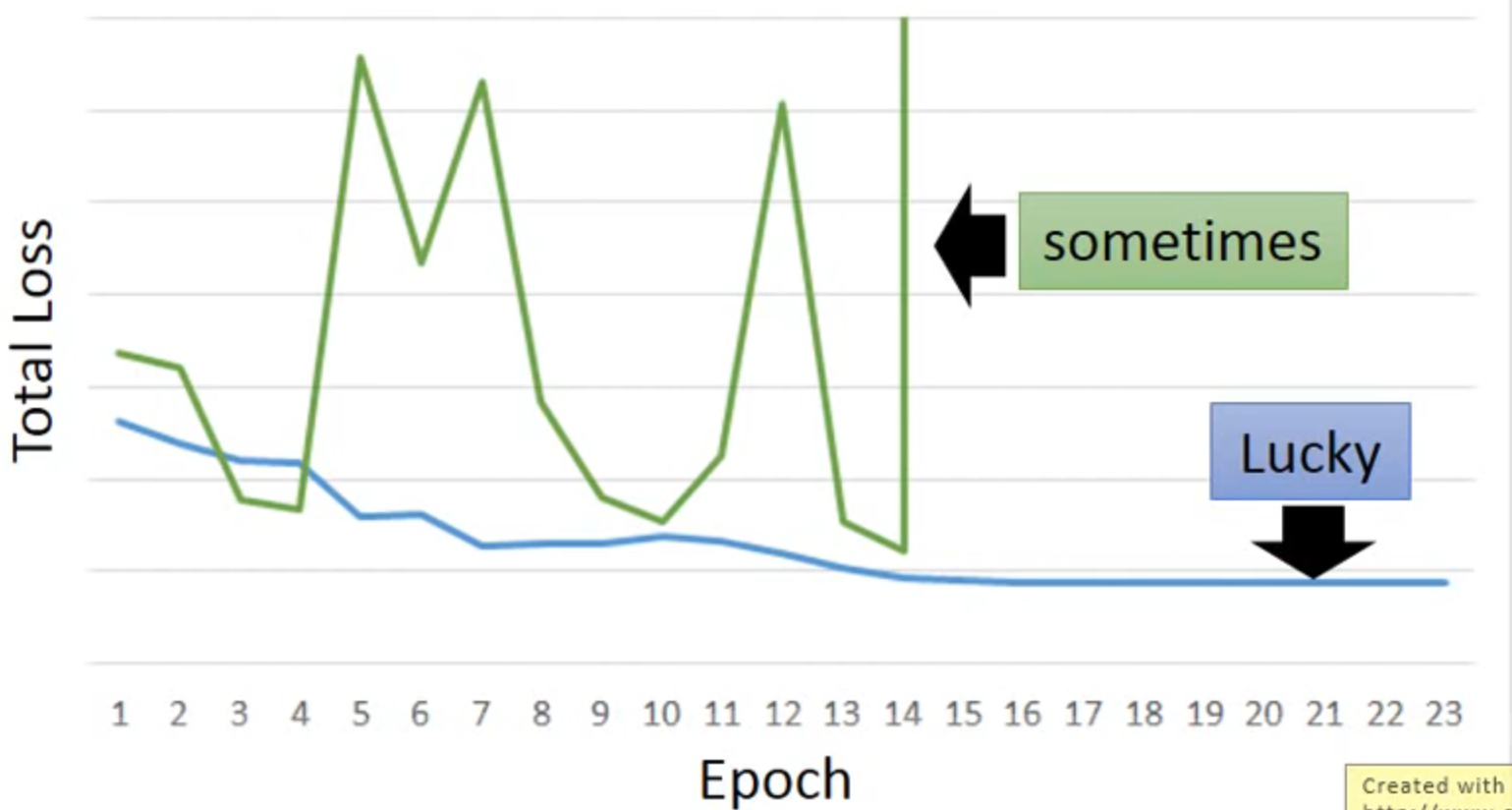
因为它的error surface 变化非常大,会有gradient vanishing的问题(同样的weight在不同的时间点被使用多次,且都是乘,指数变化很剧烈)
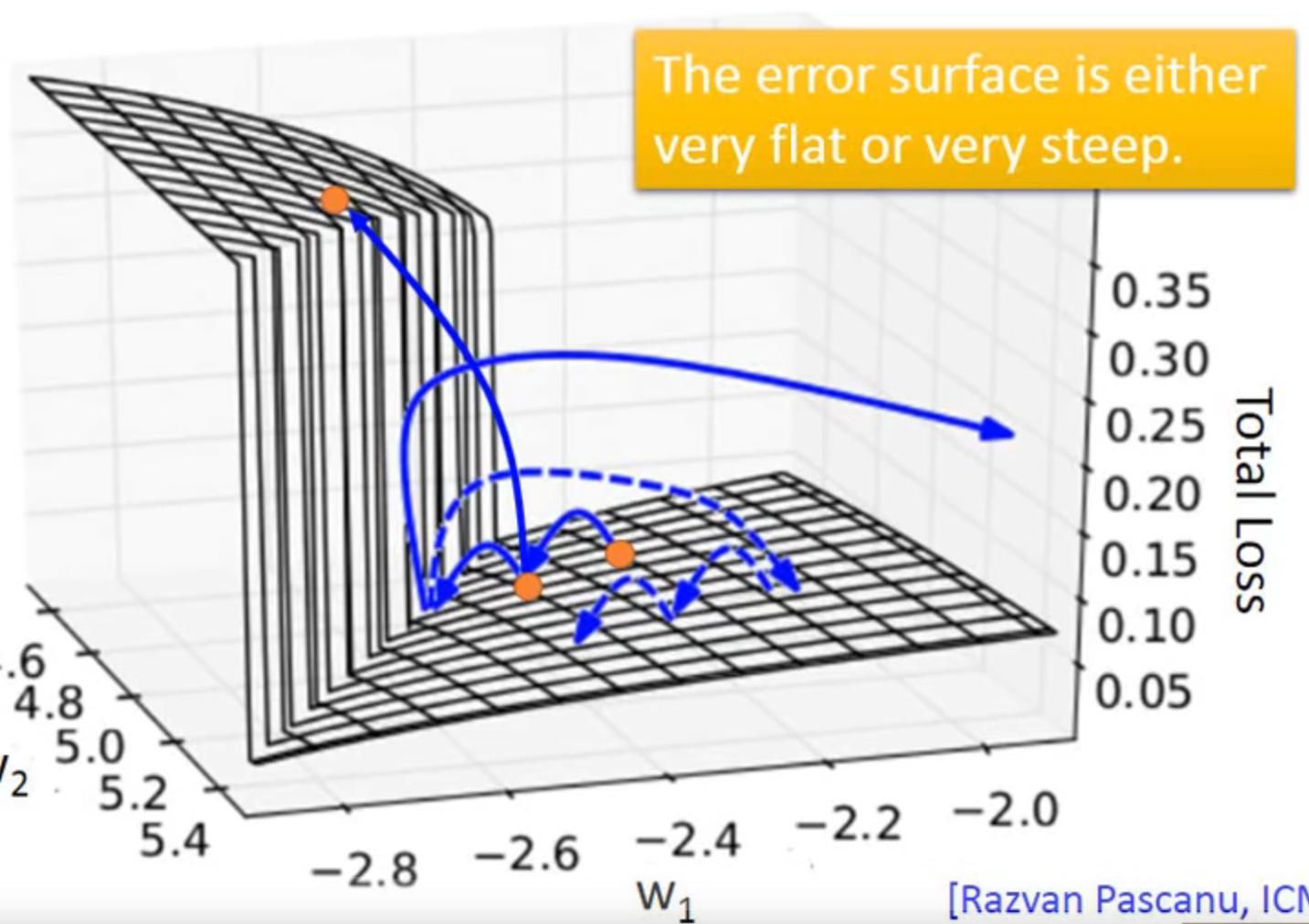
但是LSTM可以解决gradient vanishing的问题
- RNN刷新memory的值,LSTM中memory和input是相加的
- LSTM: the influence never disappears unless forget gate is closed RNN:刷新影响消失
no gradient vanishing: if forget gate is opened
other applications
上例为输入输出为数量相同的sequence
many to one : input is a vector sequence ,but output is only one vector
评论判断正面负面性质
many to many( output is short)
- 语音识别
many to many(no limitation)
- 翻译,不知道原语言和翻译后谁长谁短
- Syntactic parsing 句法分析; 结构标注; 语法解析;