CNN
Convolutional Neural Network 卷积神经网络(CNN)
convolution and the first two step
story one
- based on neuron
simplification1
problem
some patterns are much smaller than the whole image ,so we have receptive field

receptive field
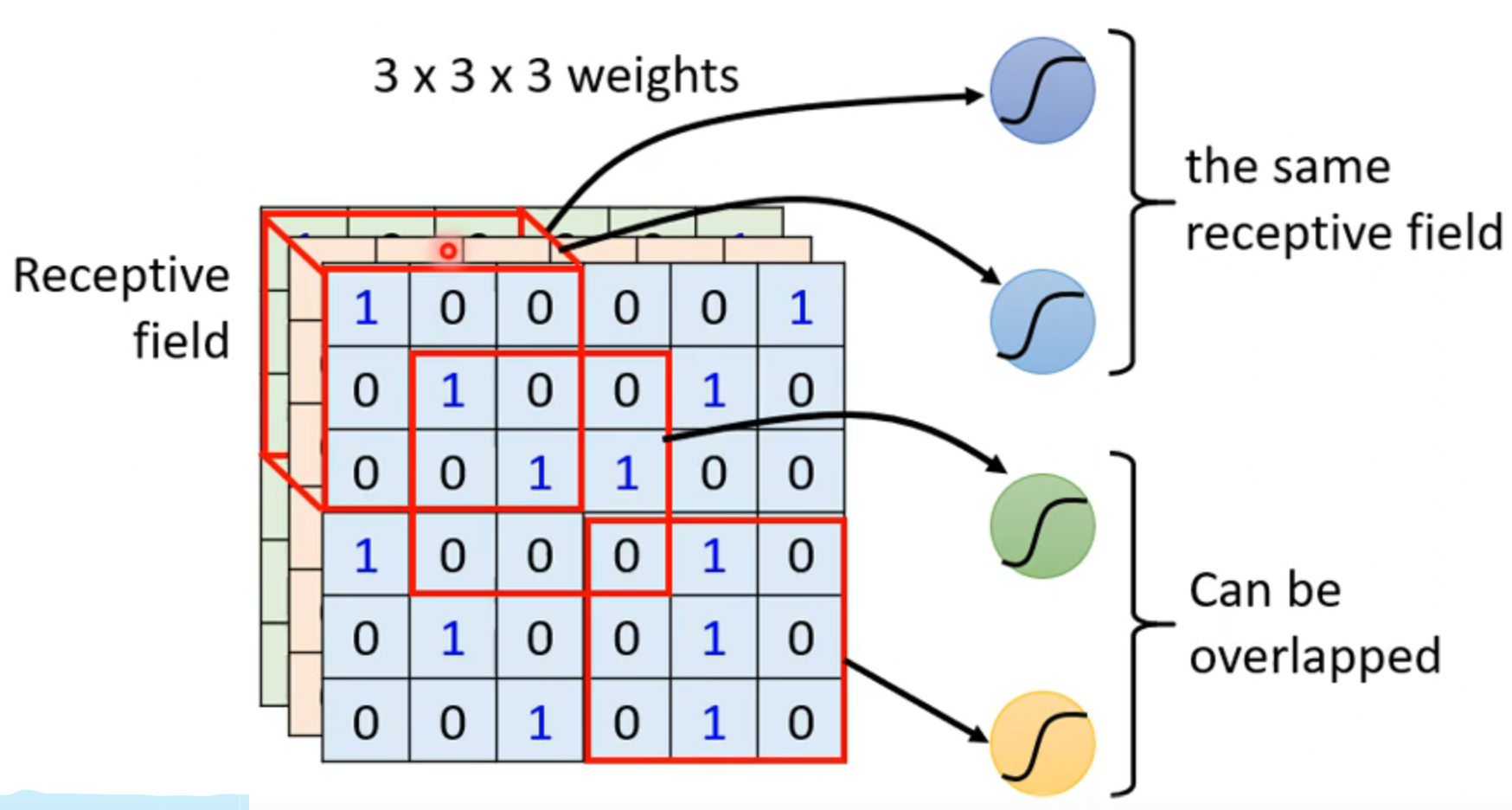
每一个neuron只看对应的receptive field ,receptive field的选择随意,人为随意设定
typical setting
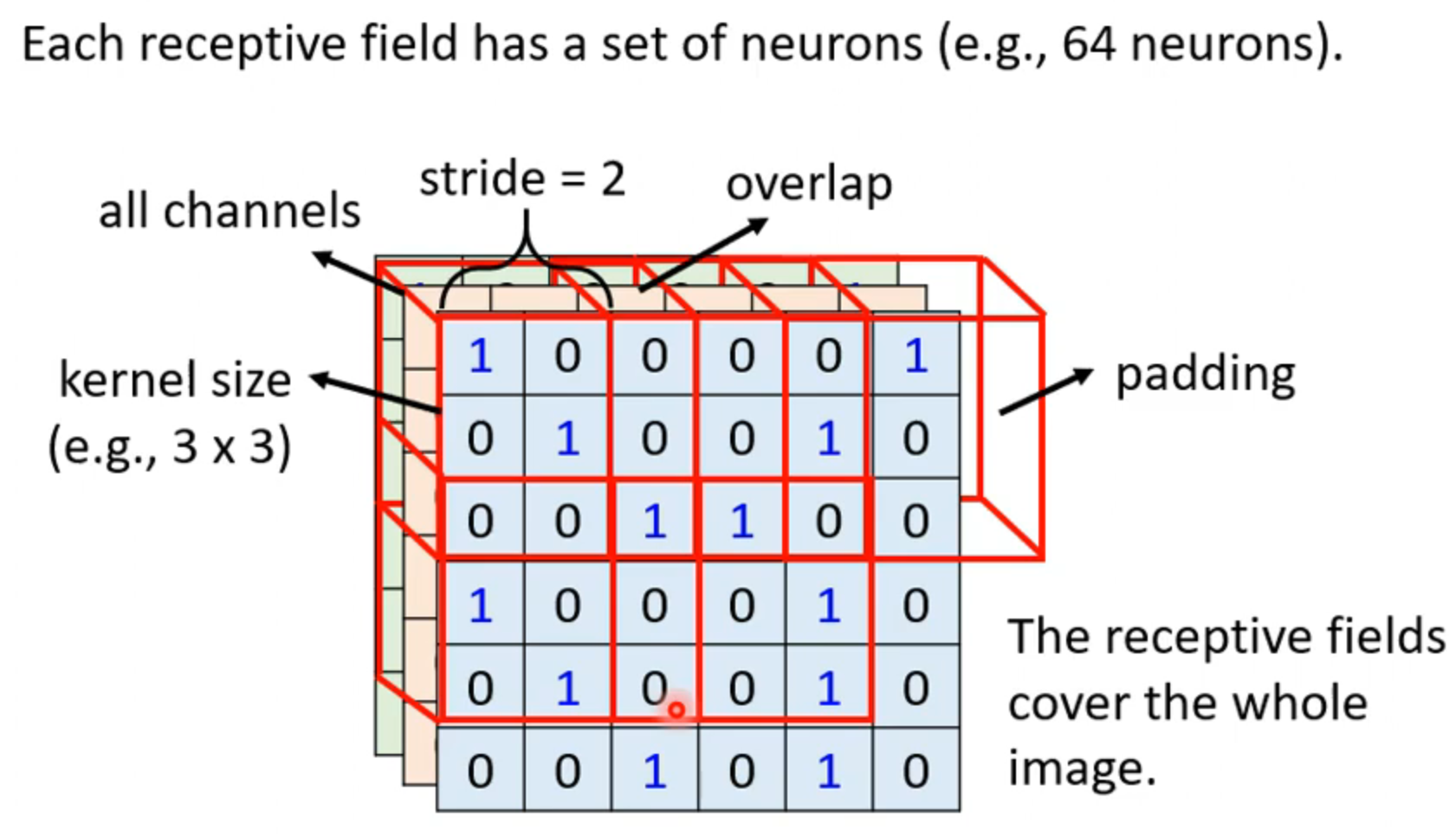
Kernel size(核心大小)一般为3X3 超出区域为padding,空白的可以用其他数据填充
simplification2
problem
the same patterns appear in different regions

parameter sharing
人为决定如何实现参数共享
typical setting
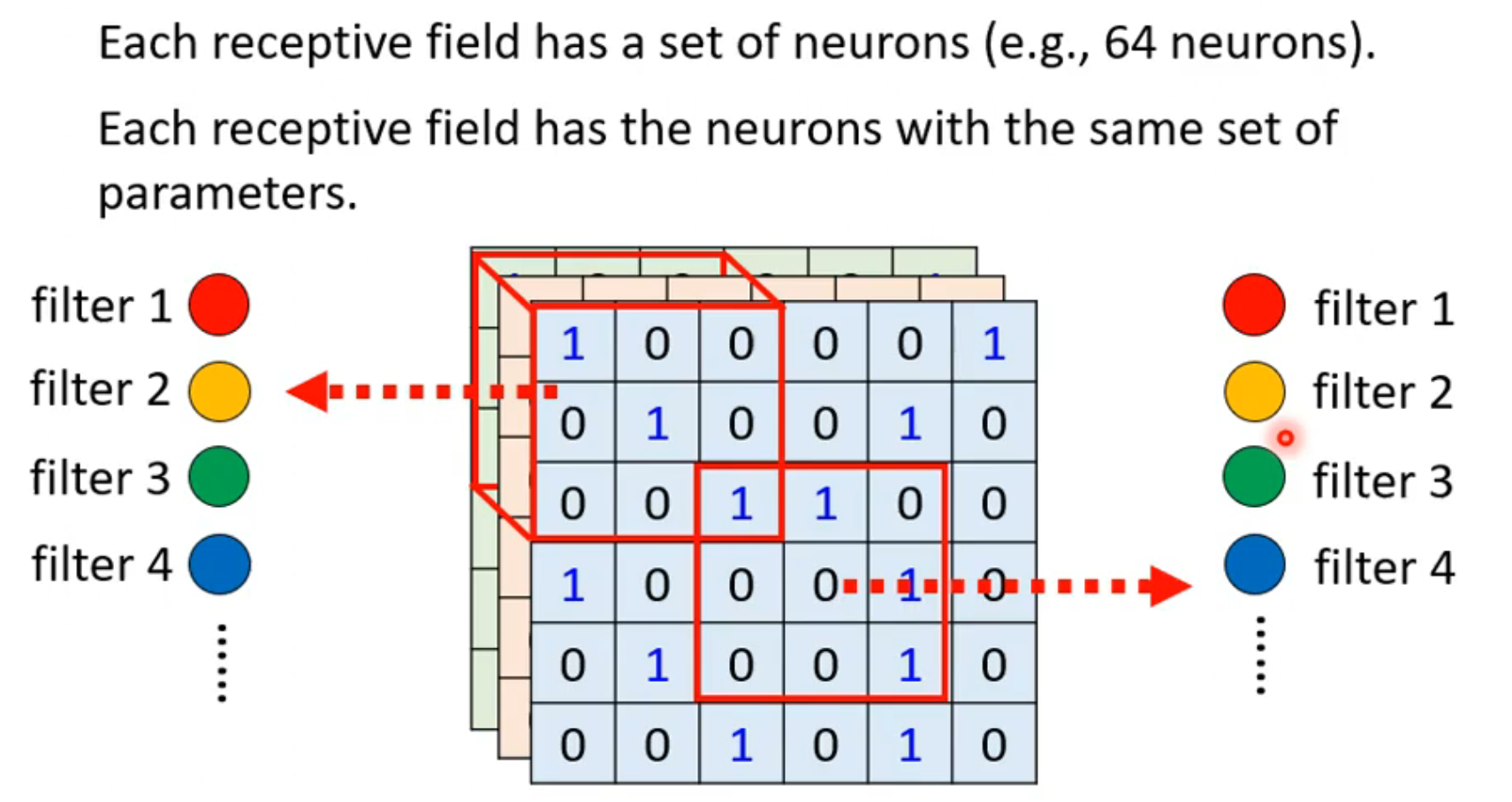
每一个receptive field有一组neuron,而图中两个receptive field共用同一组参数,即receptive field1中每个neuron的参数和receptive field中的每个对应的neuron的参数相同,这些参数称为filter
benefit of convolutional layer 卷积层的优点
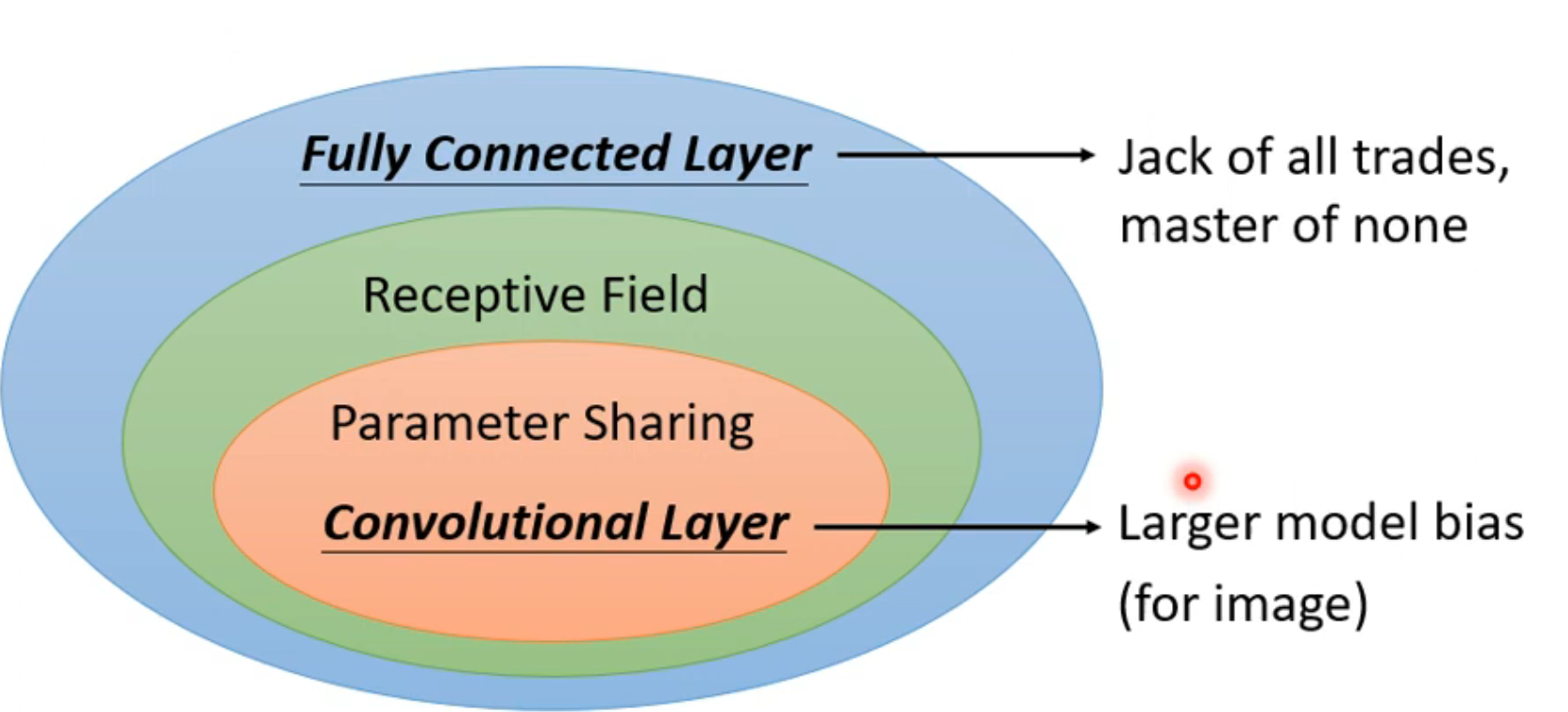
经历上述两种简化后就是应用了卷积层,而使用这种技术的神经网络就是卷积神经网络
- 虽然有很大的模型偏差,但是在图像识别上有着巨大的优势
story two
- based on filter
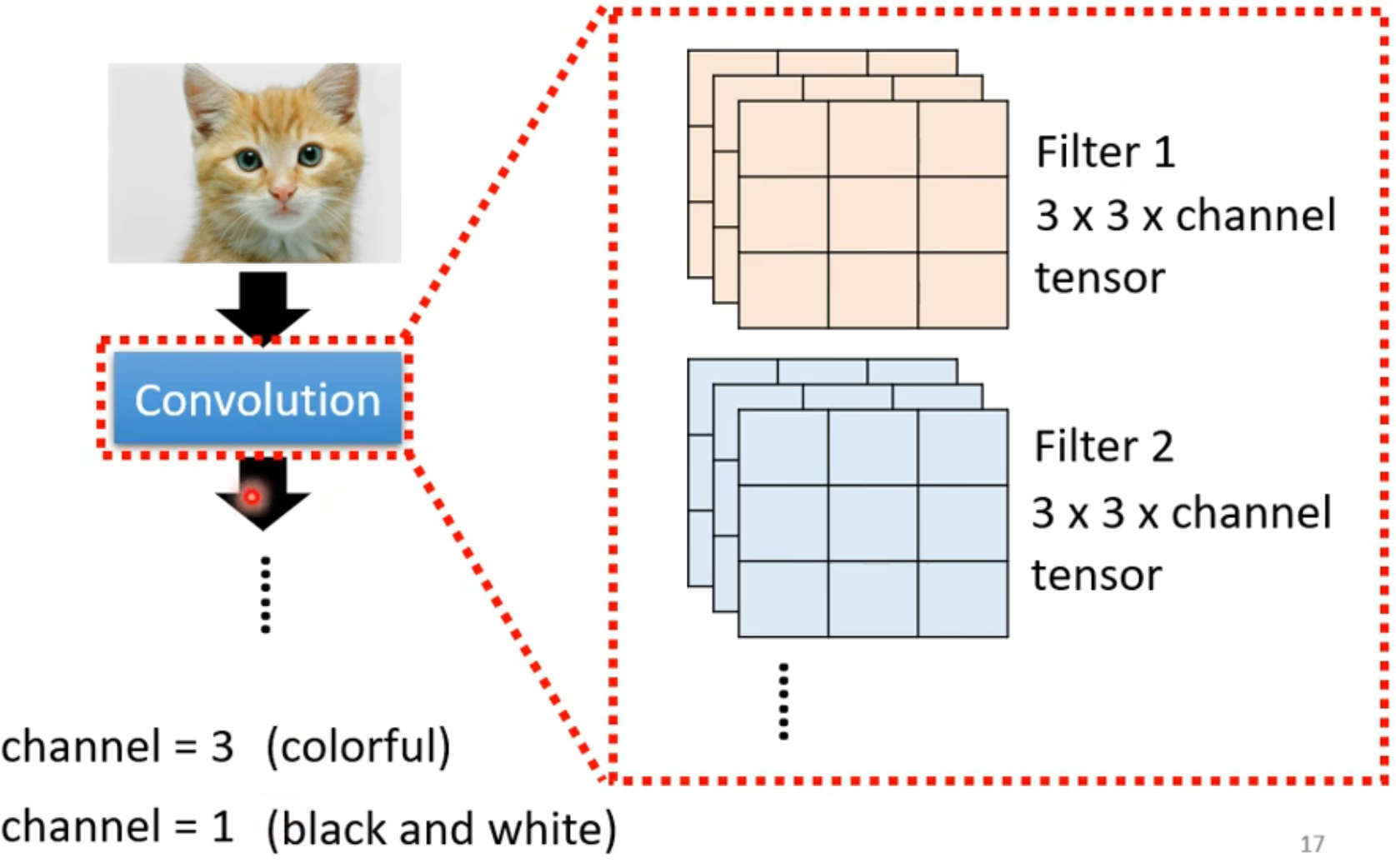
- 每一个convolutional layer 有很多filter ,每一个filter都会去detect 一个小的pattern(3x3xchannel)
channel=3 彩色 有rgb三个通道
channel=1黑白 只有一个通道
每个filter的不同channel参数不一定相同,每个filter的不同channel得到的图进行相加,最终变成一个channel
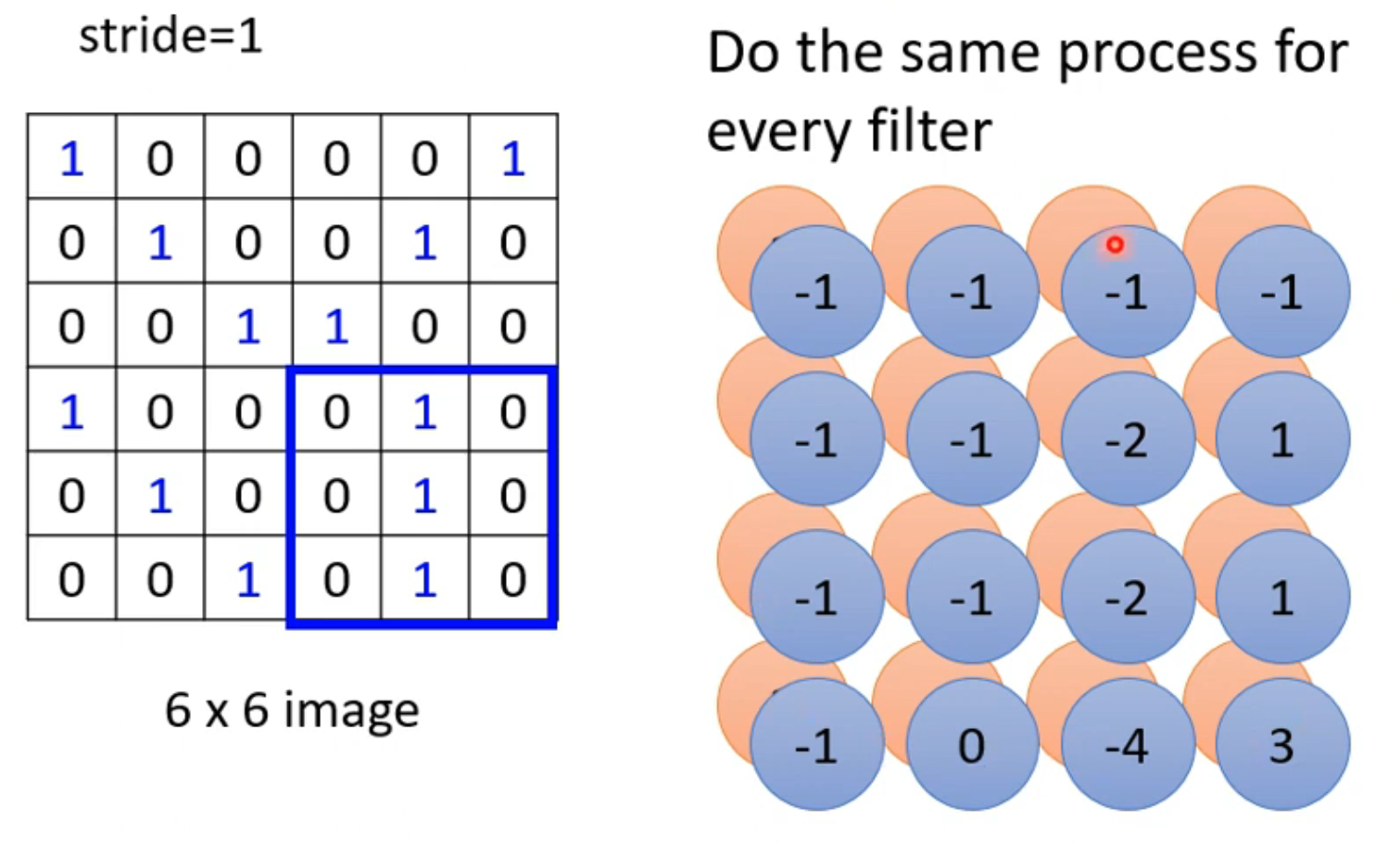
- 当filter的参数确定后,会和原数据进行矩阵乘法,(每次与3x3的范围相乘,结果会形成新的数据图,为 feature map ,同样的操作要对每一个filter进行
- filter扫过整张图片的过程就是convolution
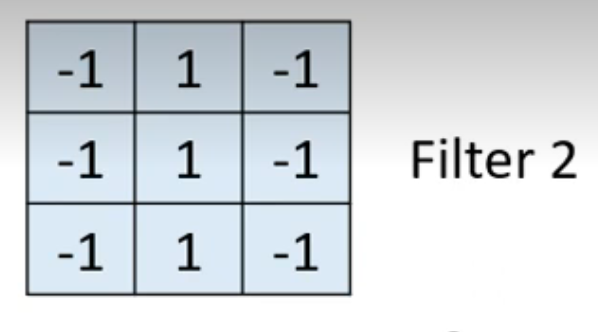
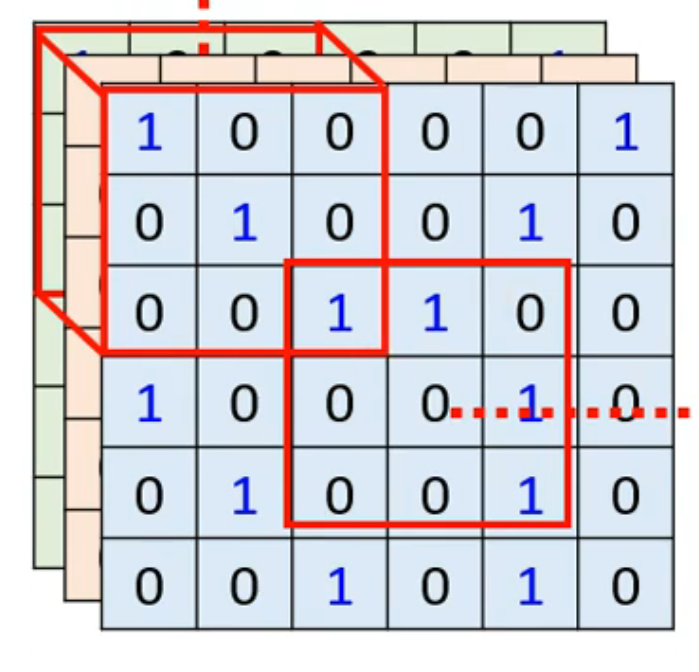
- 因为原来有64个filter,所以有64个feature map,所有的map堆叠在一起形成一张新的图片,新图片有64个channel,新的filter有64个channel
- 注意新图的3x3对应原来9x9大小的数据
simplification3
problem
subsampling the pixels will not change the object,偶数像素的拿掉,奇数的抽掉不会改变图像
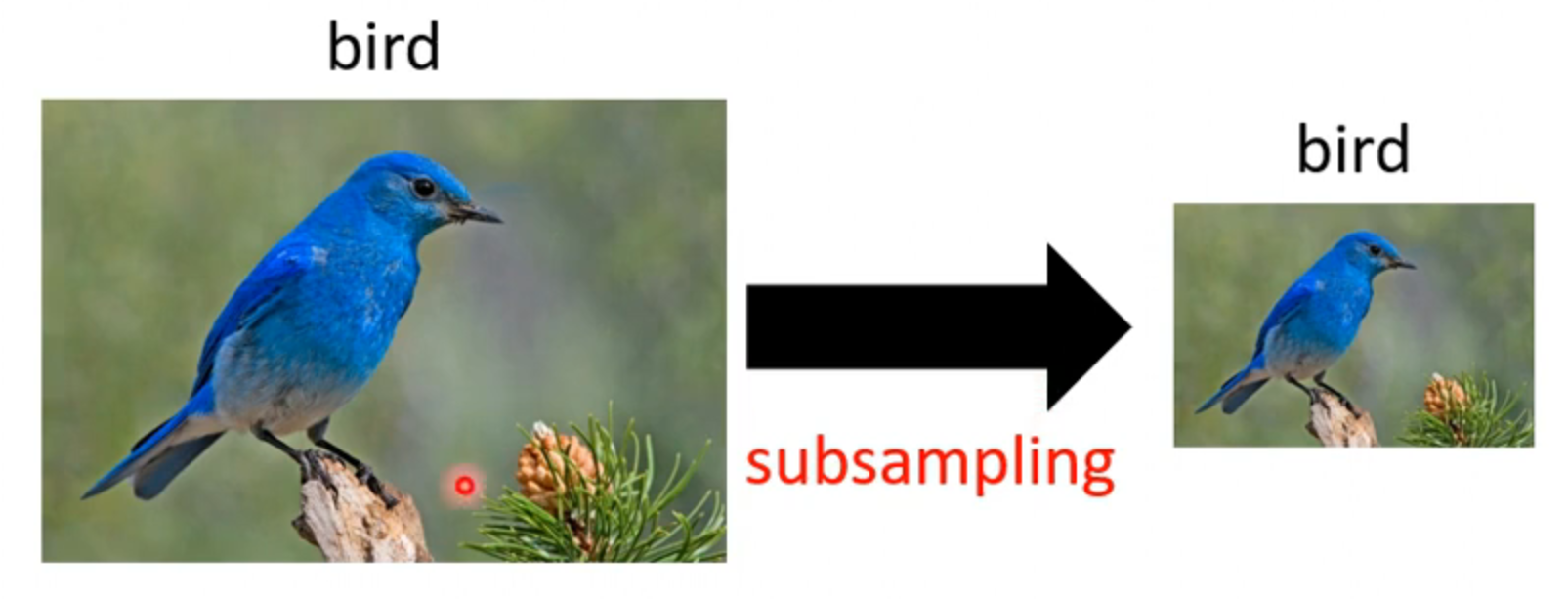
pooling
有很多pooling的方法,比如 max pooling ,mean pooling
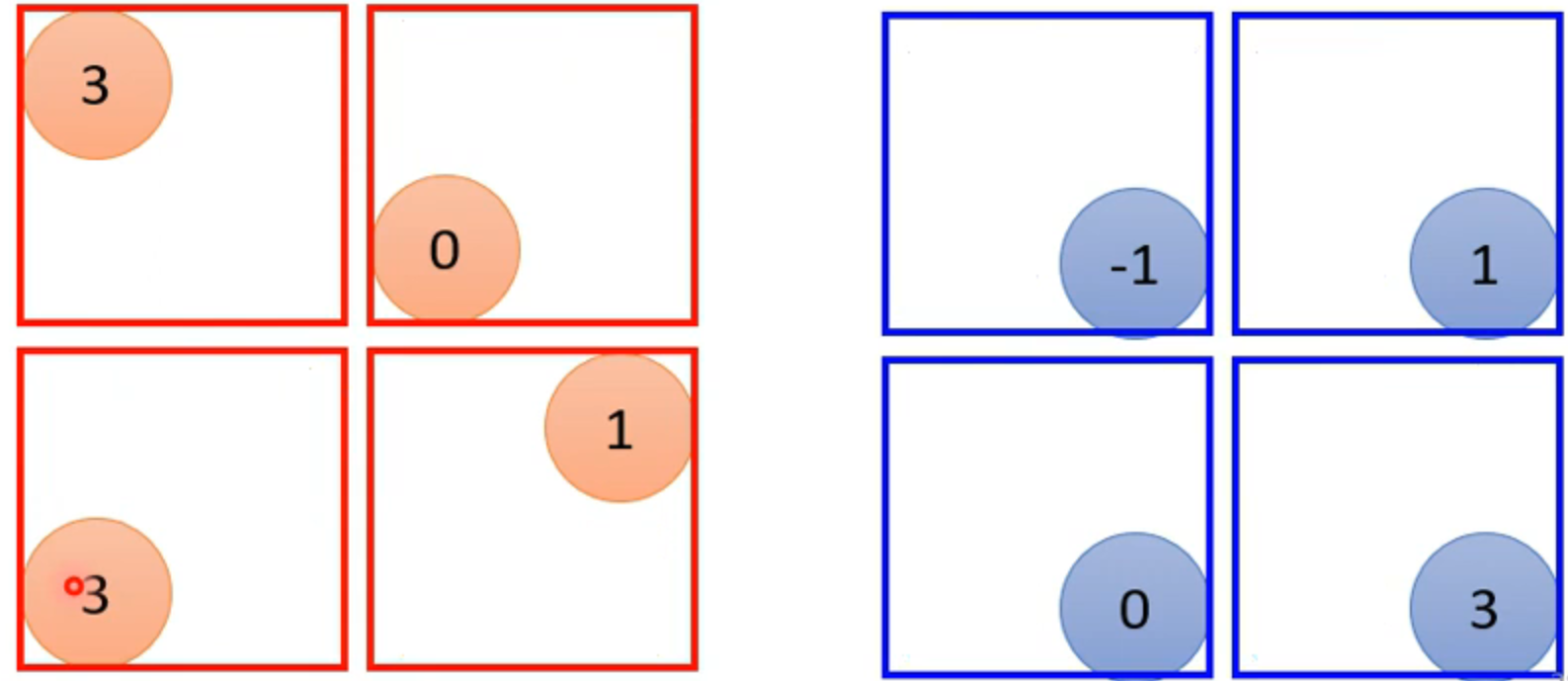
max pooling
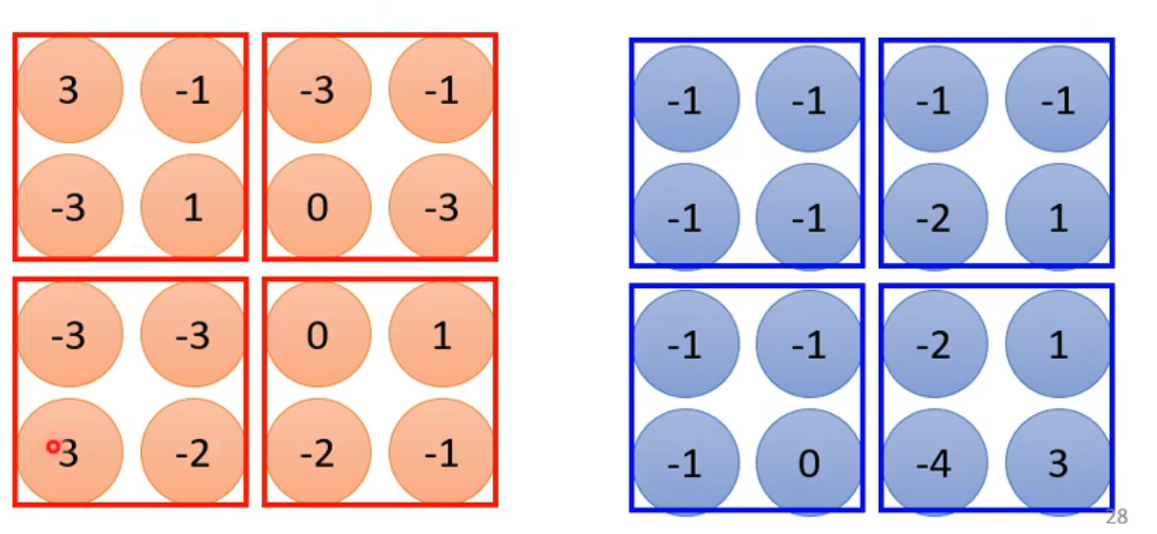
上图是根据filter1 和2 写出的两个feature map,现在将4个分成一组,max poling是只取一组中最大的拿一个,其余的全部舍弃。
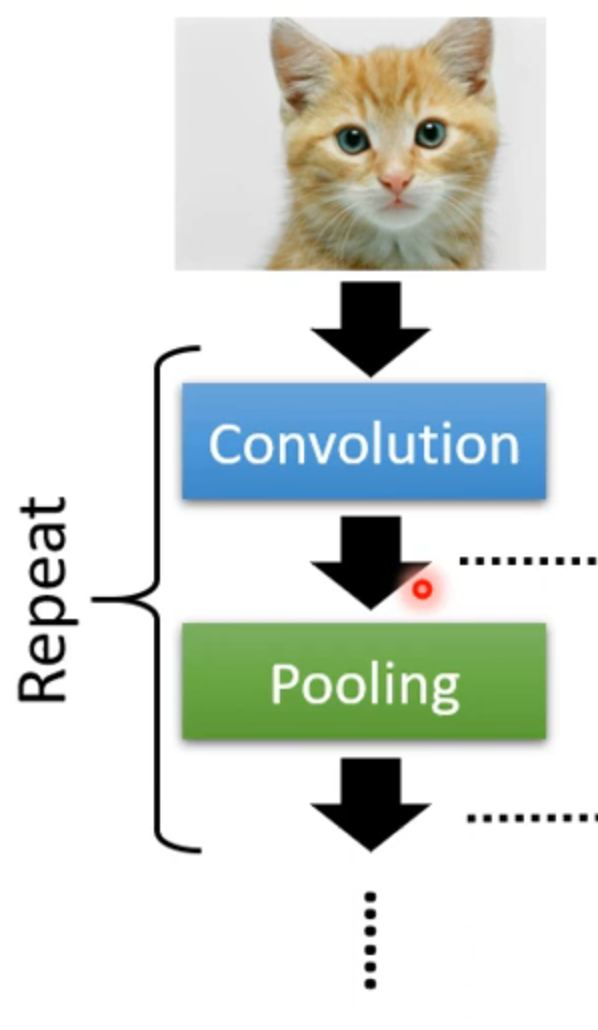
the whole CNN
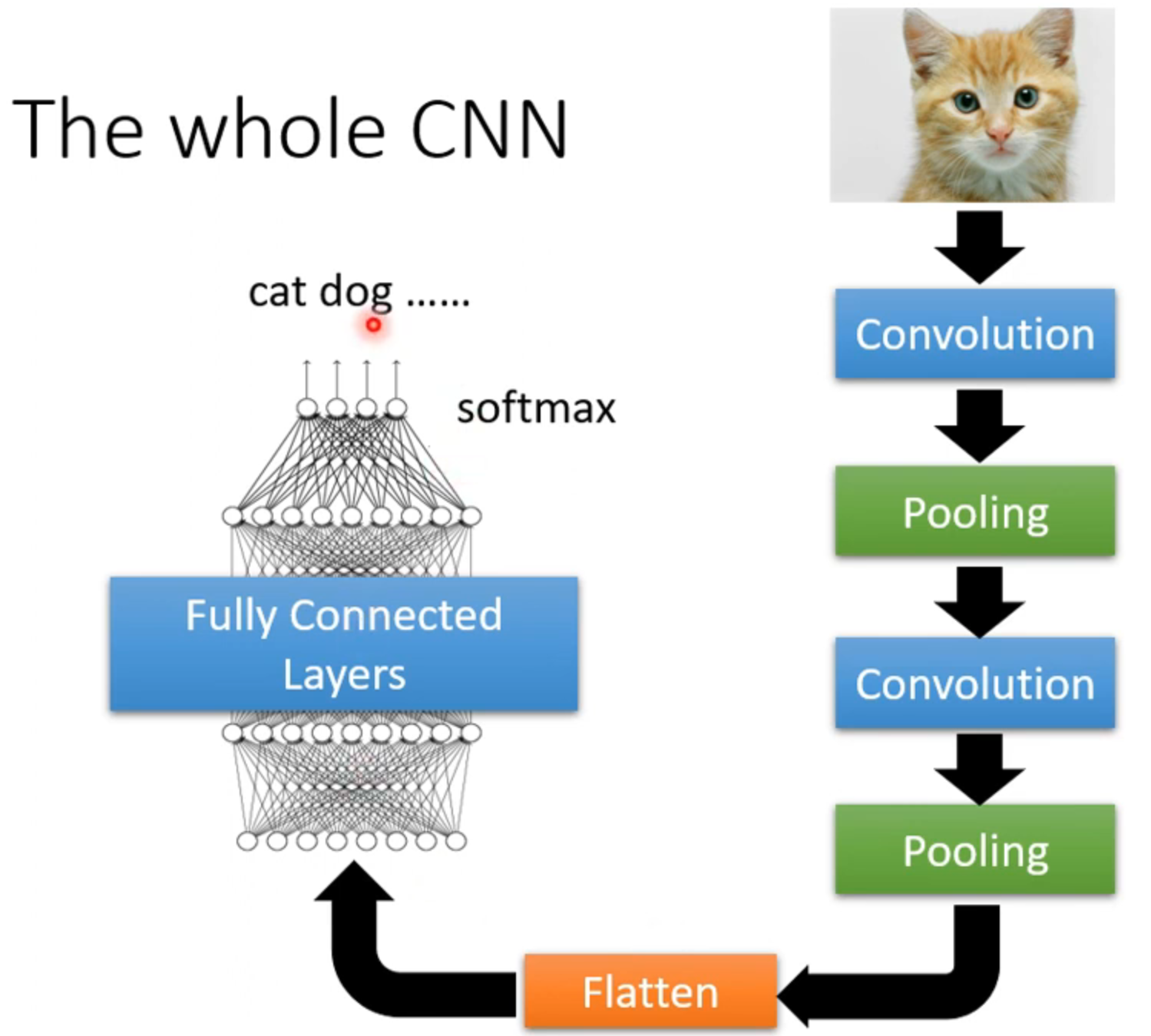
flatten是把图像上矩阵拉直成一个一个向量,然后进行fully connected layers,然后可能需要过softmax,获得最终的模型
不能处理图像放大缩小,旋转的识别,所以需要进行data augmentation(对数据进行放大缩小旋转)
other applications
- playing go( alpha go (没用pooling))
- speech 语音
- natural language processing