自监督学习
Self-supervised learning 自监督学习
introduction
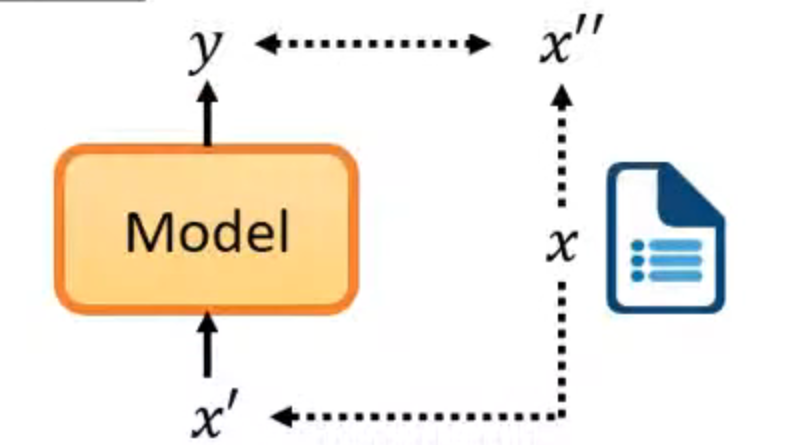
输入没有label,用x的一部分当作label
BERT
train skills
masking input
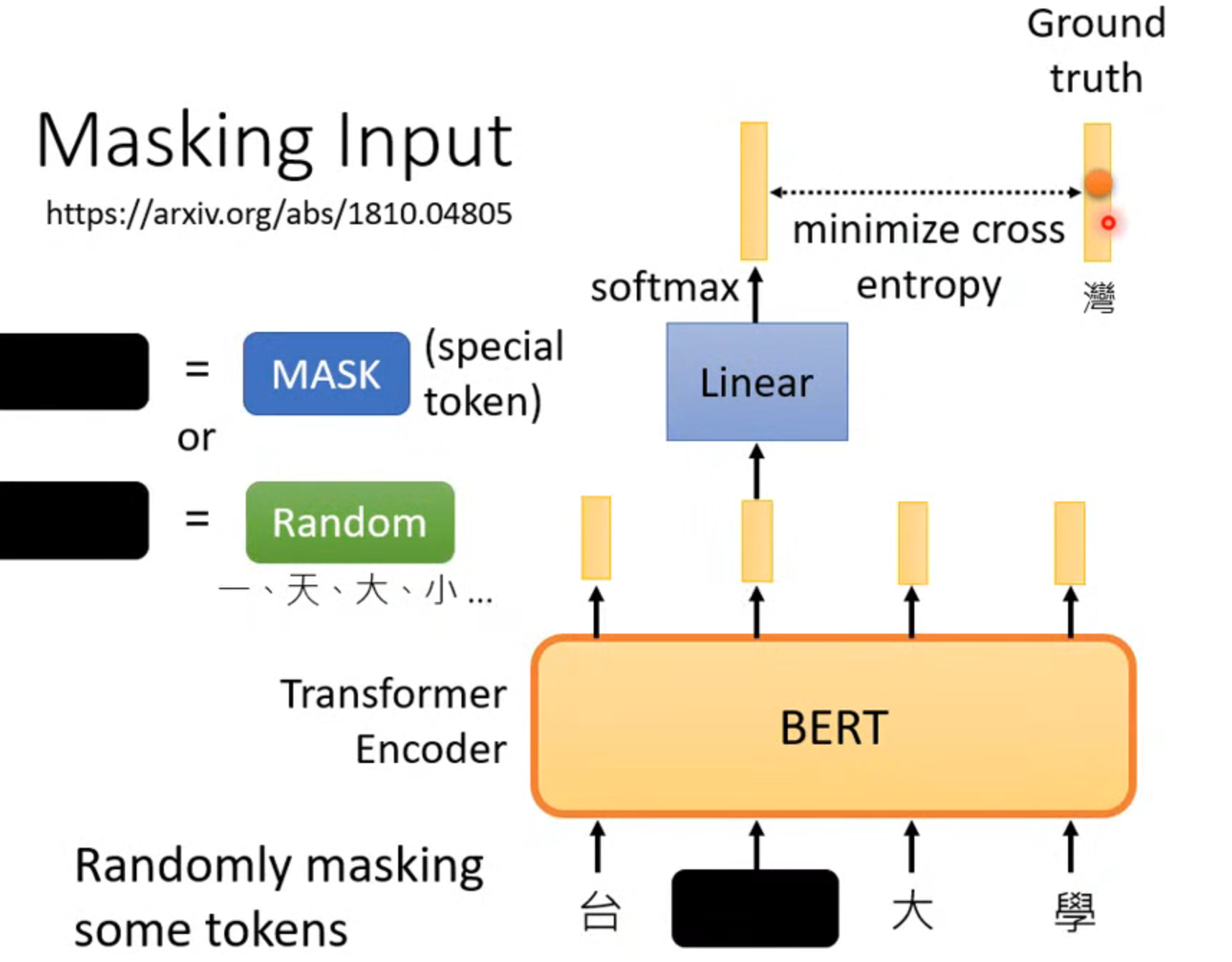
将输入盖住一部分,盖住的token可以是一个固定的也可以是随机的字,然后让bert输出,做一个分类,看最后那个字独热编码概率最大,并且让输出的字尽可能是湾
next sentence prediction
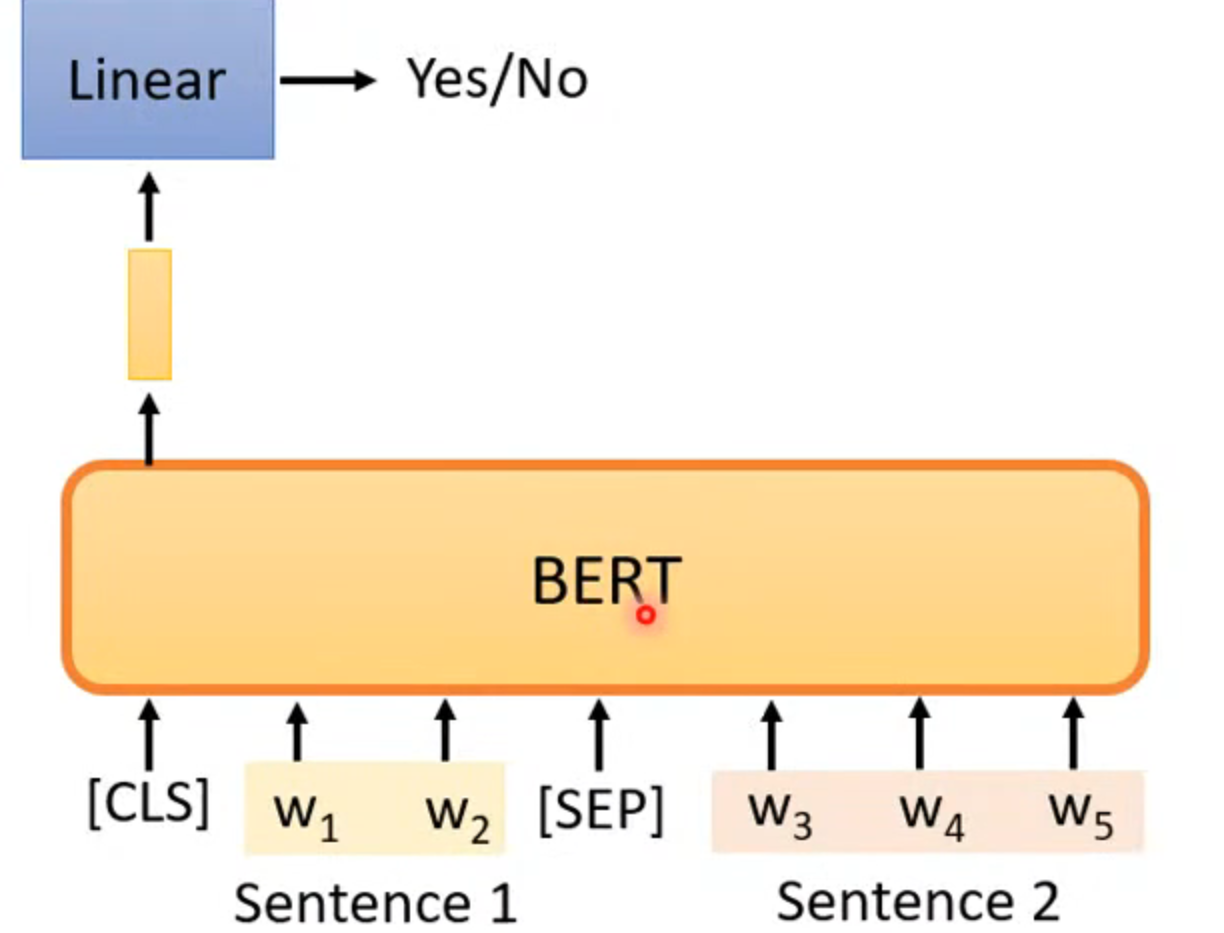
根据cls来判断后面是不是两个相连的句子,但是这个训练没什么效果
application
BERT被用在很多模型中,被称为
- downstream tasks
- the task we care
- we have a little bit labeled data
应用过程
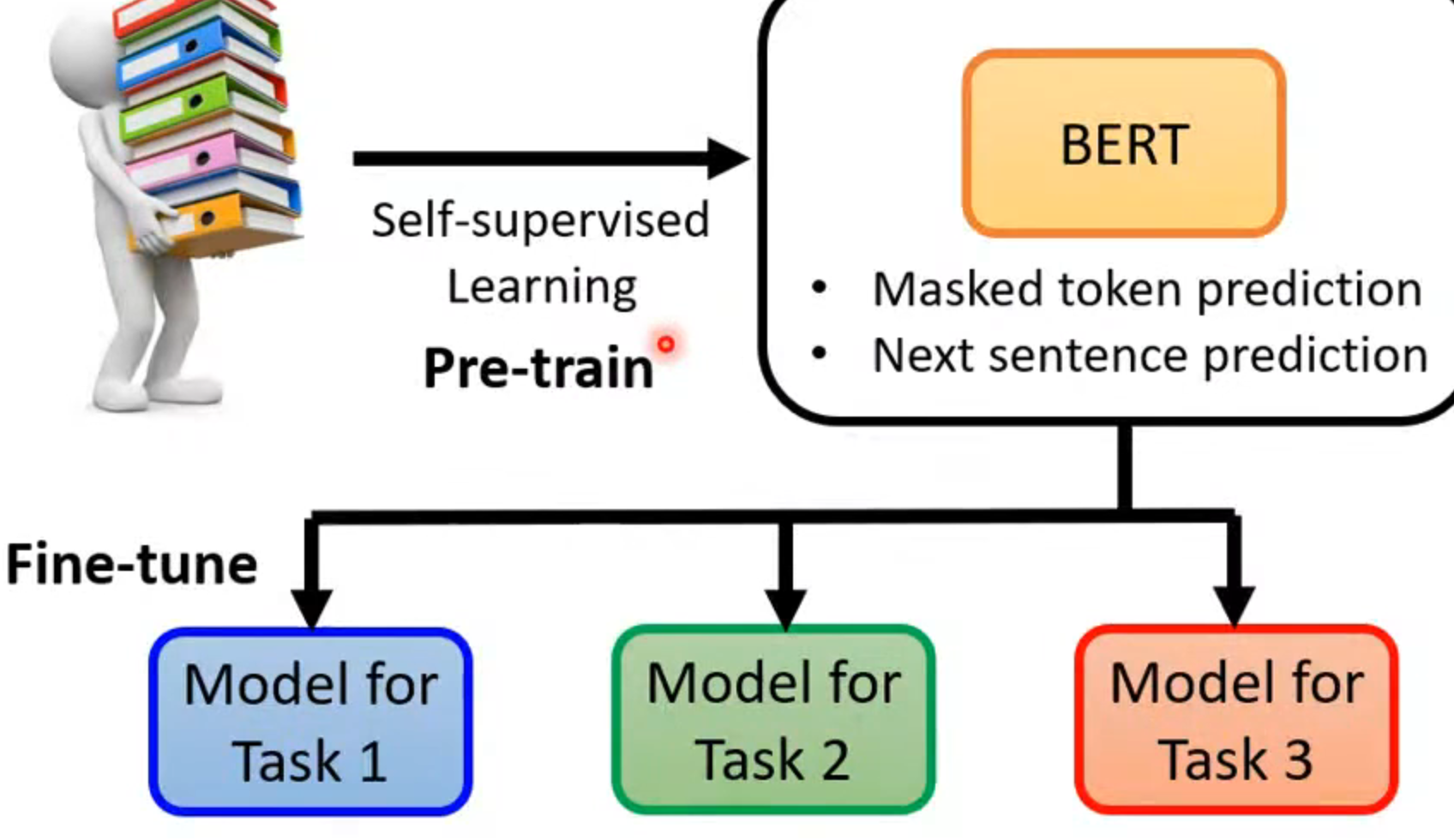
先pre-train 一个model,然后通过fine-tune(微调)从而得到更多的model
测试fine-tune后性能
GLUE(general language understanding evaluation)
有九个任务,fine-tune后测试表现

how to use BERT
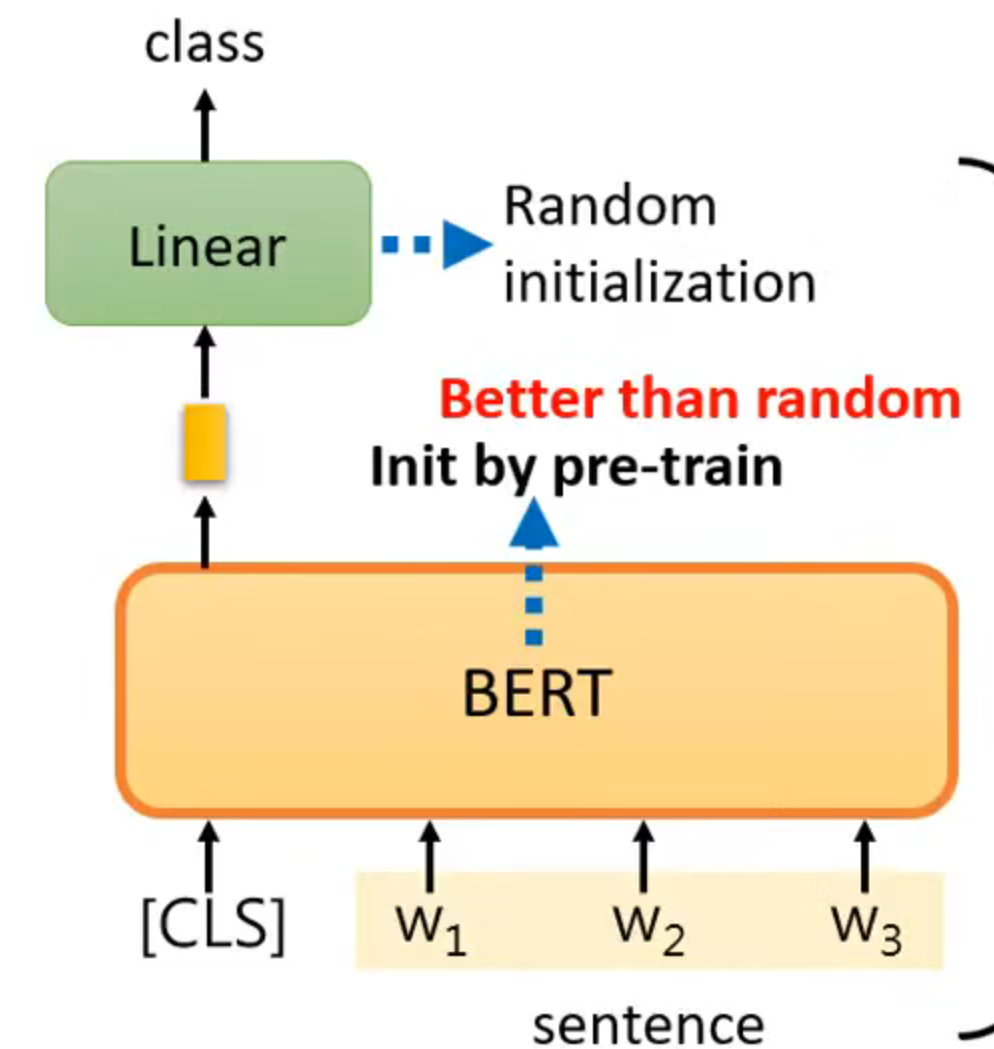
case 1
input: sequence
output: class
eg: sentiment analysis
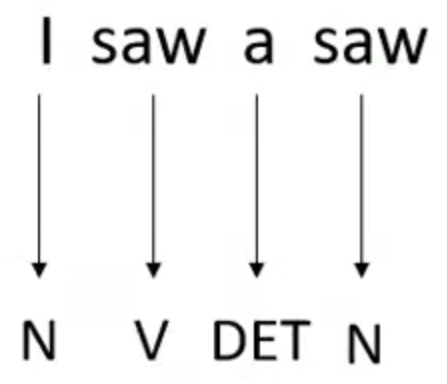
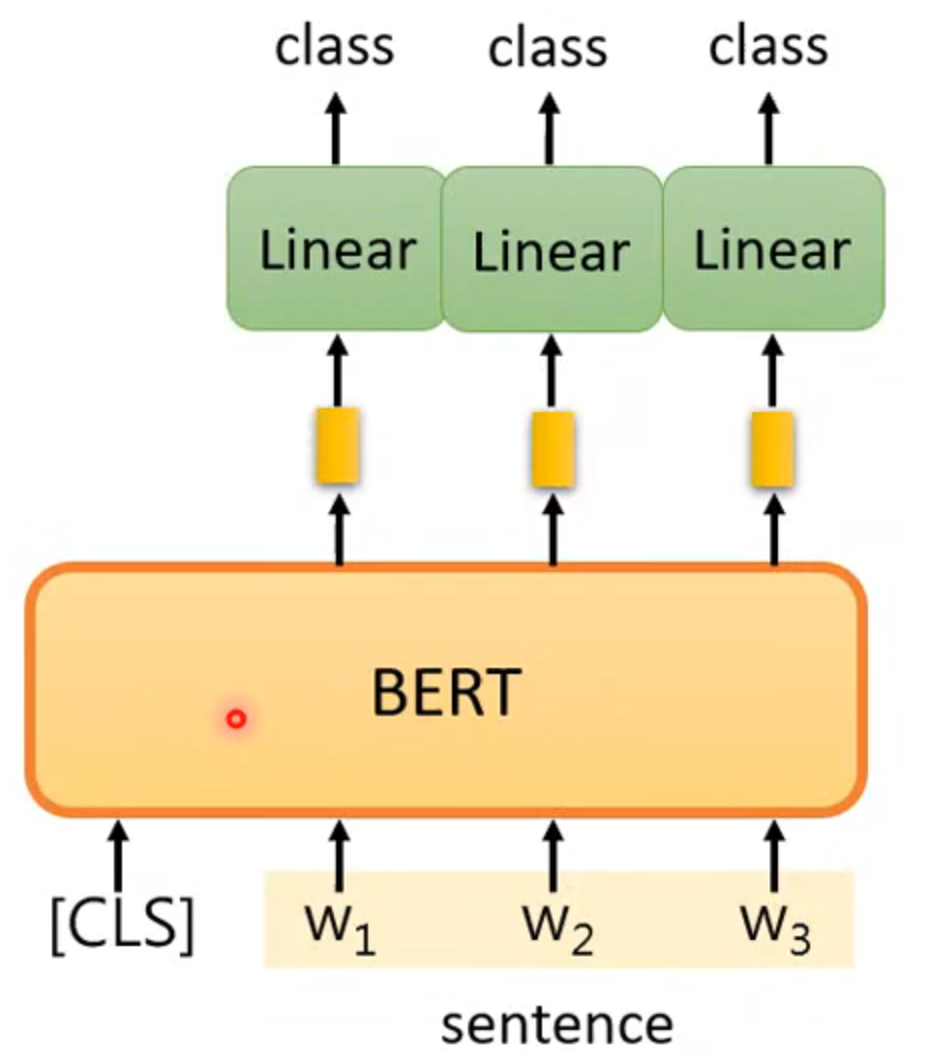
case 2
input: sequence
output: same as input
eg: POS tagging
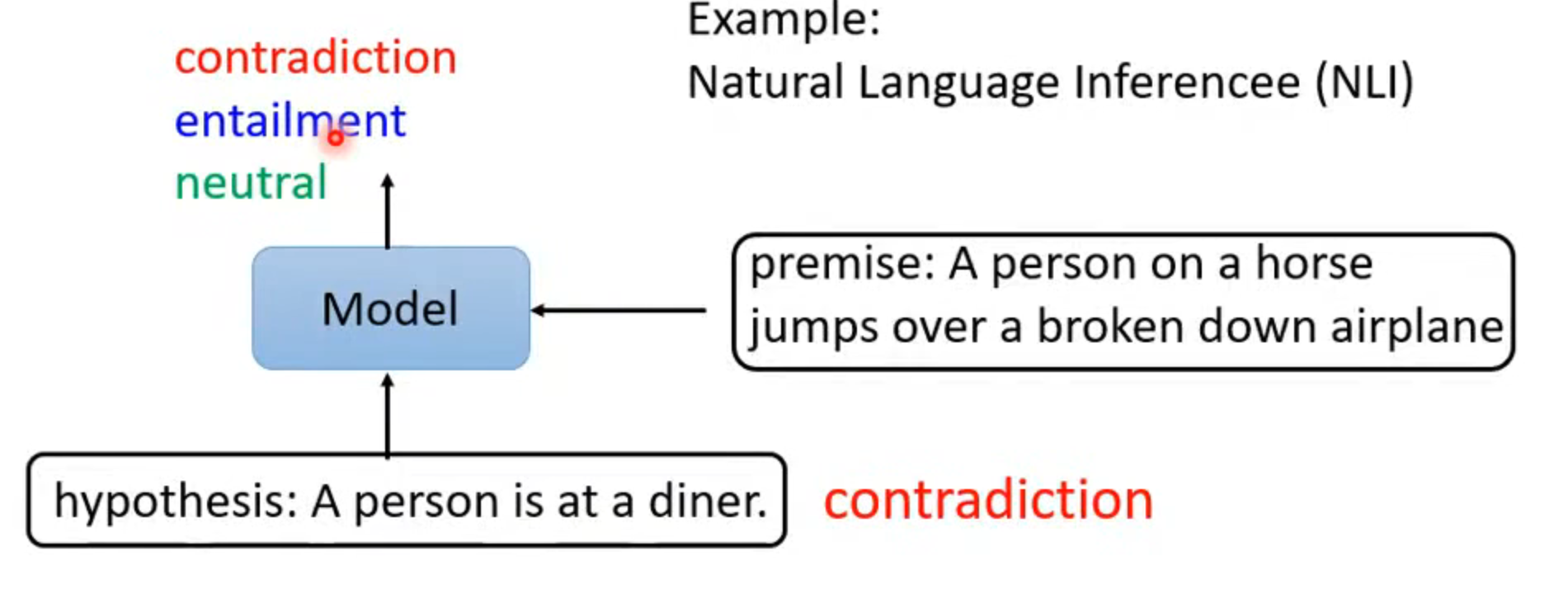
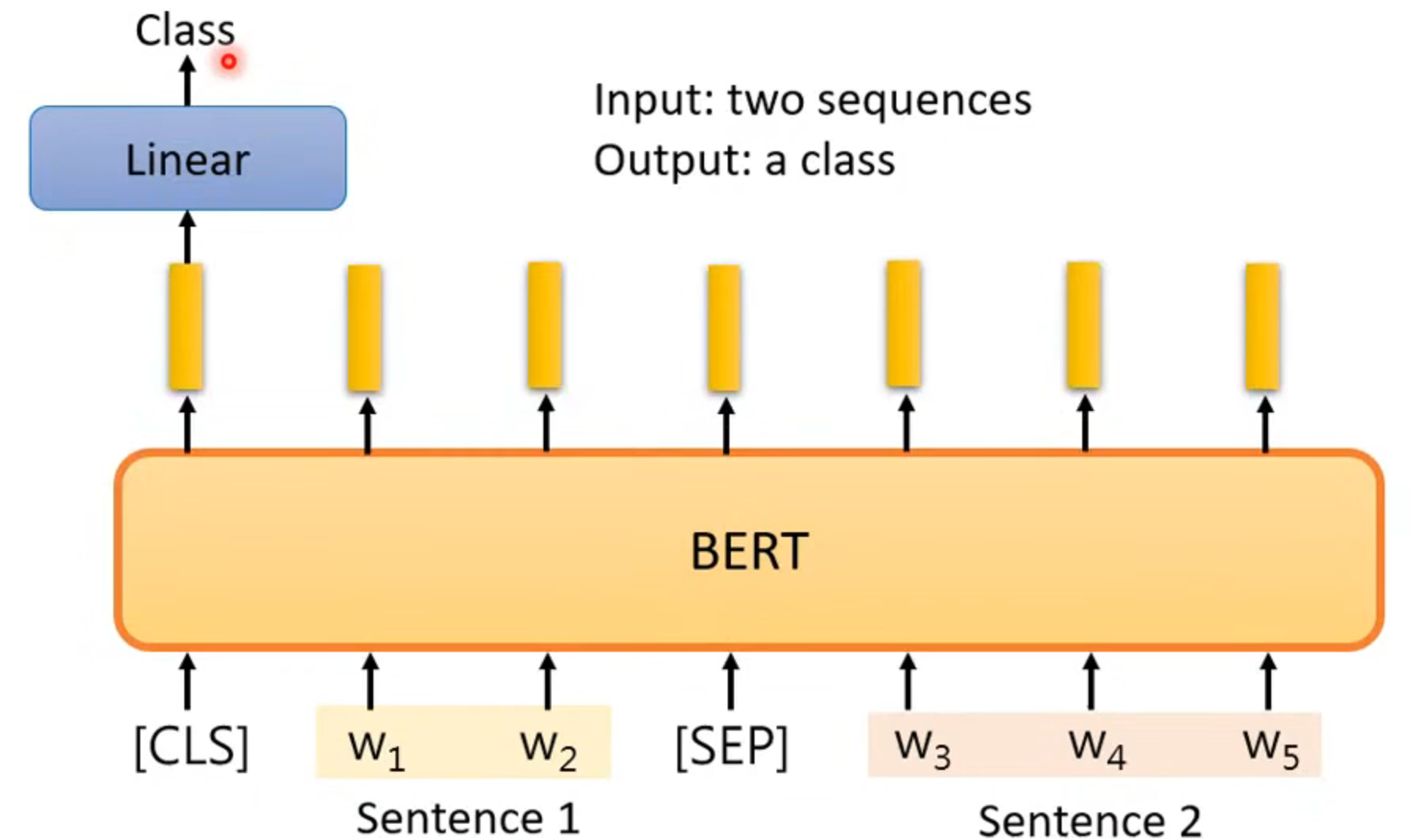
case 3
input: two sequences
output: a class
eg: natural language inference NLI 自然语言推理,用于分析和理解自然语言文本之间的关系,例如判断两个句子之间的蕴含、矛盾或中立关系。
case 4
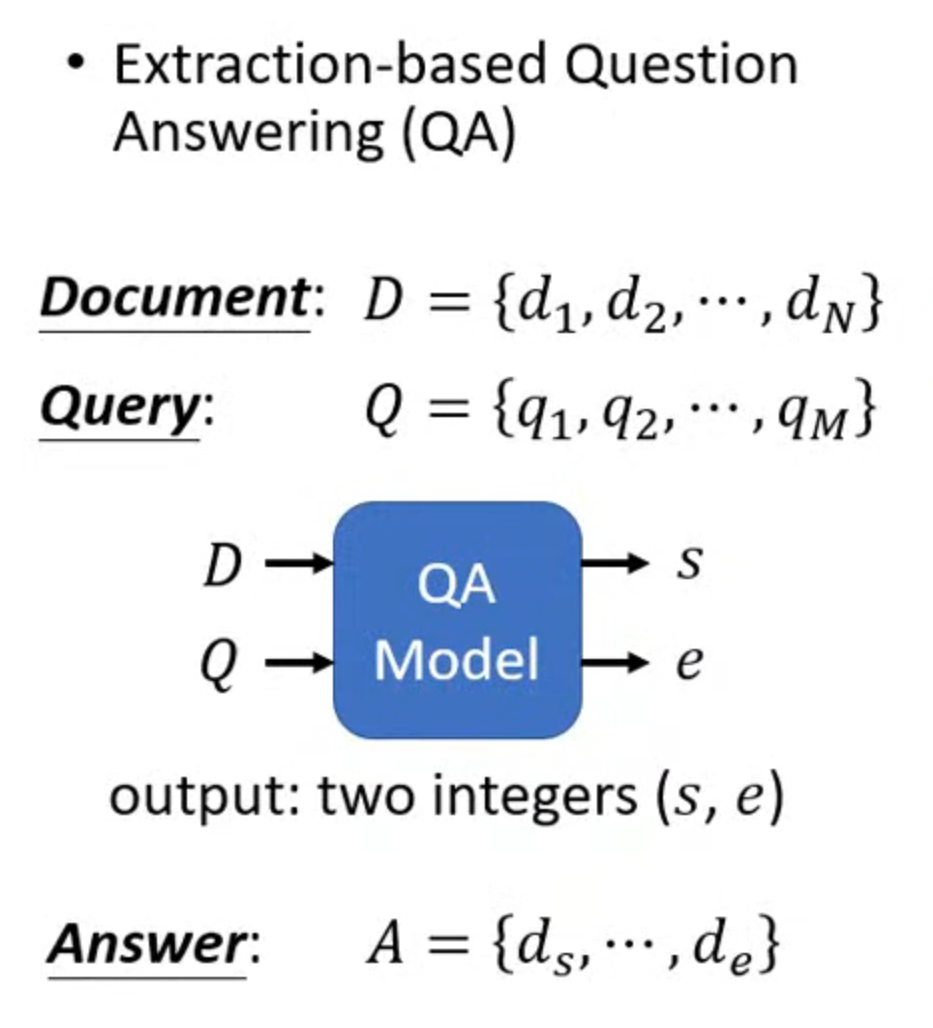
基于摘要的QA,输出只有两个整数,在序号为这两个数之间的内容就是答案
why dose BERT work
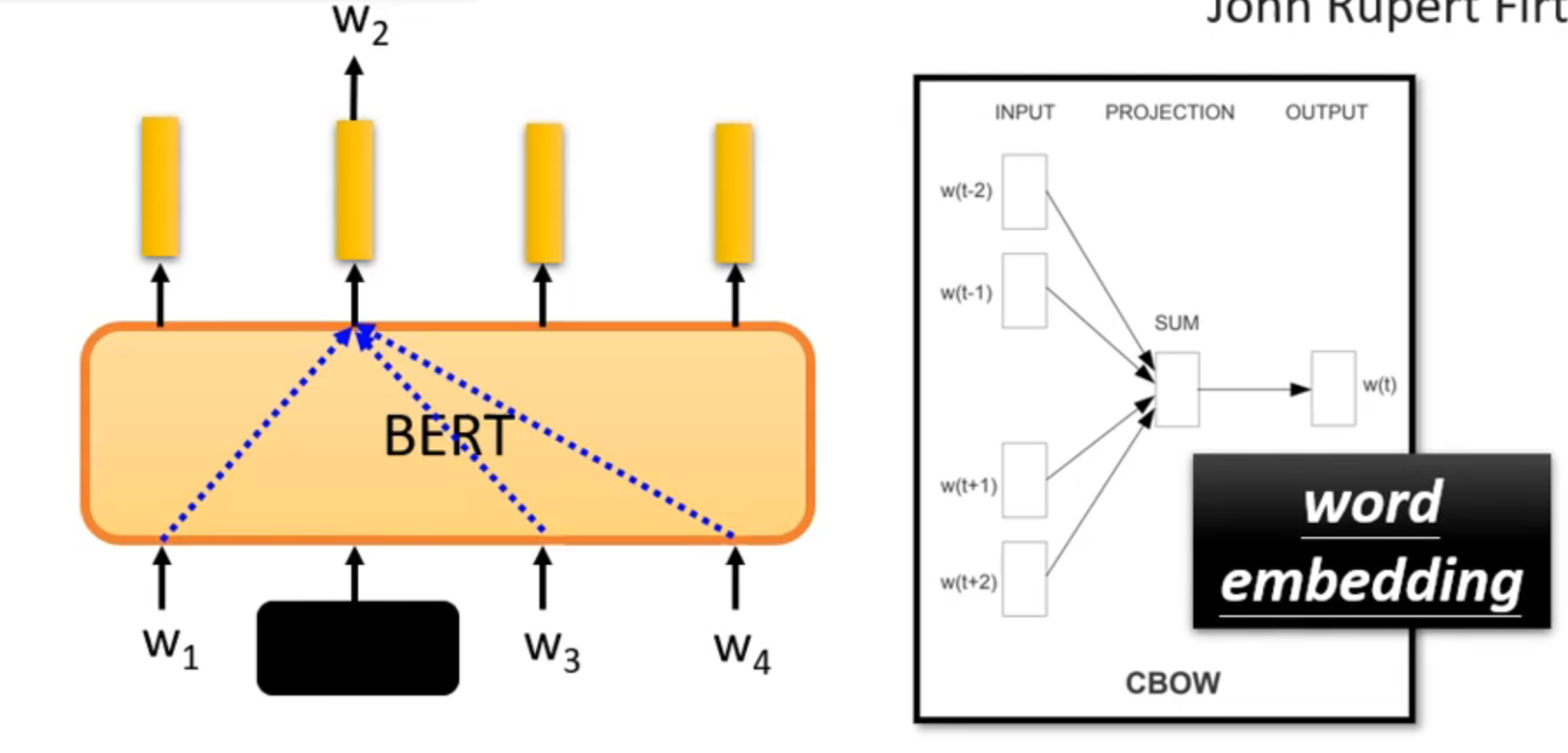
you know aword by the company it keeps
contextualized word embedding
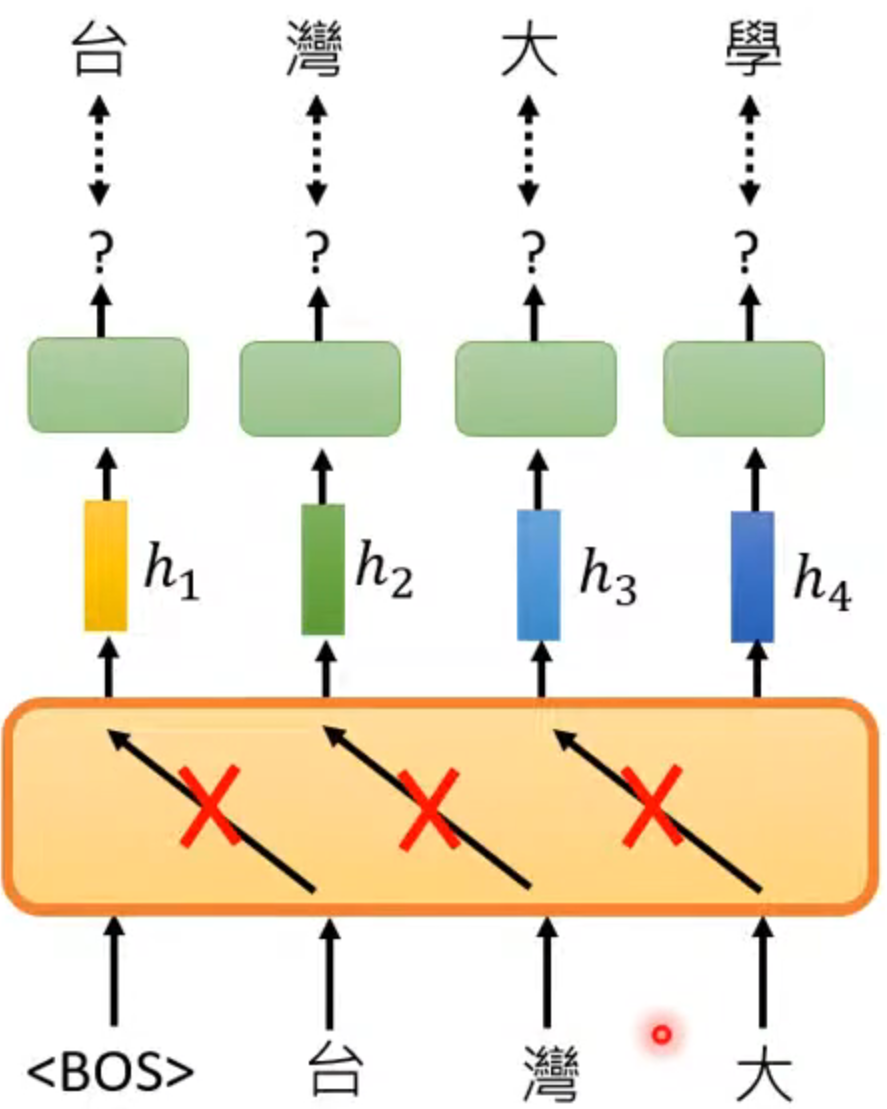
GPT
function
predict next token
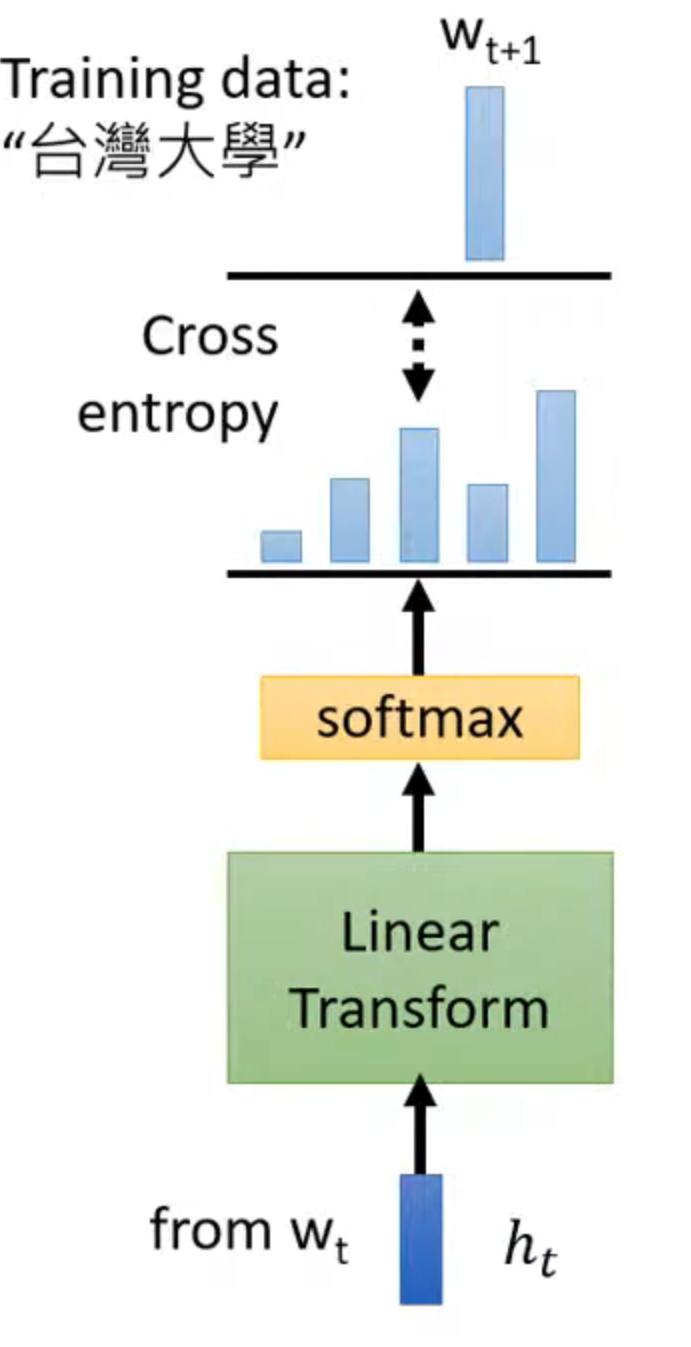
但和transformer的decoder类似,只能看见之前的输入,不能看见之后的
in-context learning
few-shot learning
要求翻译成法语,只提供几个范例

one-shot learning
给要求但只给一个例子

zero-shot learning
只有要求,没有例子
